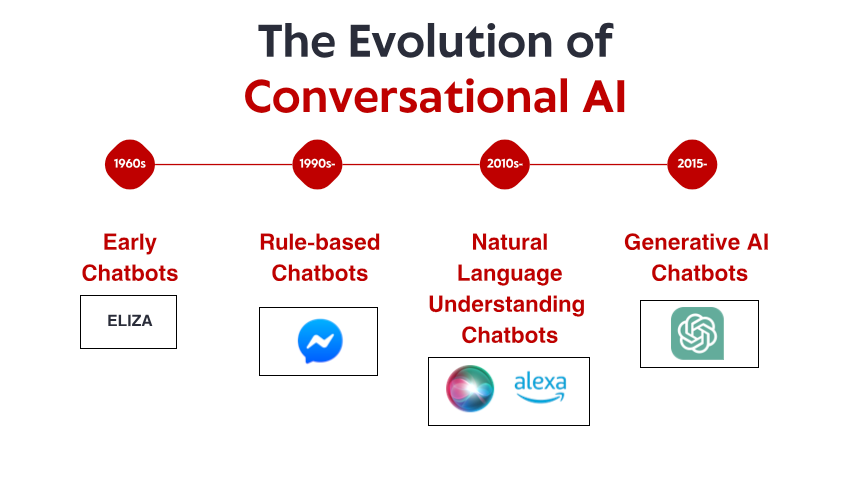
Скромний початок: ранні системи, засновані на правилах
Історія розмовного ШІ починається в 1960-х роках, задовго до того, як смартфони та голосові помічники стали основними продуктами домашнього вжитку. У невеликій лабораторії Массачусетського технологічного інституту комп’ютерний науковець Джозеф Вайзенбаум створив те, що багато хто вважає першим чат-ботом: ELIZA. Розроблена для імітації роджеріанського психотерапевта, ELIZA працювала з простими правилами зіставлення шаблонів і заміни. Коли користувач вводить «Мені сумно», ELIZA може відповісти «Чому тобі сумно?» – створення ілюзії розуміння шляхом переформулювання тверджень у запитання.
Те, що робило ELIZA чудовою, так це не її технічна складність – за сучасними стандартами програма була неймовірно простою. Швидше, це був глибокий вплив, який він мав на користувачів. Незважаючи на те, що вони знали, що вони спілкуються з комп’ютерною програмою без фактичного розуміння, багато людей сформували емоційні зв’язки з ЕЛІЗОЮ, поділяючись глибоко особистими думками та почуттями. Це явище, яке сам Вайзенбаум вважав тривожним, виявило щось фундаментальне про людську психологію та нашу готовність антропоморфізувати навіть найпростіші розмовні інтерфейси.
Протягом 1970-х і 1980-х років чат-боти на основі правил наслідували шаблон ELIZA з поступовими вдосконаленнями. Такі програми, як PARRY (симуляція параноїдального шизофреніка) і RACTER (який «автор» книги під назвою «Поліцейська борода наполовину сконструйована») залишалися в рамках парадигми, заснованої на правилах, – використовуючи заздалегідь визначені шаблони, відповідність ключових слів і шаблонні відповіді.
Ці ранні системи мали серйозні обмеження. Вони насправді не могли розуміти мову, вчитися на взаємодії або адаптуватися до несподіваних вхідних даних. Їхні знання були обмежені будь-якими правилами, які їхні програмісти чітко визначили. Коли користувачі неминуче виходили за ці межі, ілюзія інтелекту швидко руйнувалася, відкриваючи механічну природу. Незважаючи на ці обмеження, ці піонерські системи заклали фундамент, на якому будуватиметься весь майбутній розмовний ШІ.
Те, що робило ELIZA чудовою, так це не її технічна складність – за сучасними стандартами програма була неймовірно простою. Швидше, це був глибокий вплив, який він мав на користувачів. Незважаючи на те, що вони знали, що вони спілкуються з комп’ютерною програмою без фактичного розуміння, багато людей сформували емоційні зв’язки з ЕЛІЗОЮ, поділяючись глибоко особистими думками та почуттями. Це явище, яке сам Вайзенбаум вважав тривожним, виявило щось фундаментальне про людську психологію та нашу готовність антропоморфізувати навіть найпростіші розмовні інтерфейси.
Протягом 1970-х і 1980-х років чат-боти на основі правил наслідували шаблон ELIZA з поступовими вдосконаленнями. Такі програми, як PARRY (симуляція параноїдального шизофреніка) і RACTER (який «автор» книги під назвою «Поліцейська борода наполовину сконструйована») залишалися в рамках парадигми, заснованої на правилах, – використовуючи заздалегідь визначені шаблони, відповідність ключових слів і шаблонні відповіді.
Ці ранні системи мали серйозні обмеження. Вони насправді не могли розуміти мову, вчитися на взаємодії або адаптуватися до несподіваних вхідних даних. Їхні знання були обмежені будь-якими правилами, які їхні програмісти чітко визначили. Коли користувачі неминуче виходили за ці межі, ілюзія інтелекту швидко руйнувалася, відкриваючи механічну природу. Незважаючи на ці обмеження, ці піонерські системи заклали фундамент, на якому будуватиметься весь майбутній розмовний ШІ.
Революція знань: експертні системи та структурована інформація
У 1980-х і на початку 1990-х років відбувся розвиток експертних систем – програм штучного інтелекту, розроблених для вирішення складних проблем шляхом імітації здібностей експертів-людей приймати рішення в певних областях. Незважаючи на те, що ці системи не були в основному розроблені для розмови, вони стали важливим еволюційним кроком для розмовного ШІ, запровадивши більш складне представлення знань.
Експертні системи, такі як MYCIN (яка діагностувала бактеріальні інфекції) і DENDRAL (яка ідентифікувала хімічні сполуки), організовували інформацію в структурованих базах знань і використовували механізми логічного висновку, щоб робити висновки. У застосуванні до розмовних інтерфейсів цей підхід дозволив чат-ботам перейти від простого зіставлення шаблонів до чогось схожого на міркування – принаймні у вузьких доменах.
Компанії почали впроваджувати такі практичні програми, як автоматизовані системи обслуговування клієнтів, використовуючи цю технологію. Ці системи зазвичай використовували дерева рішень і взаємодію на основі меню, а не бесіду у вільній формі, але вони являли собою перші спроби автоматизувати взаємодії, які раніше вимагали втручання людини.
Обмеження залишалися значними. Ці системи були крихкими, нездатними витончено обробляти несподівані вхідні дані. Вони вимагали величезних зусиль від інженерів знань, щоб вручну закодувати інформацію та правила. І, можливо, найголовніше, вони все ще не могли по-справжньому зрозуміти природну мову в її повній складності та неоднозначності.
Тим не менш, ця епоха встановила важливі концепції, які пізніше стануть вирішальними для сучасного розмовного ШІ: структуроване представлення знань, логічний висновок і спеціалізація домену. Сцена готувалася для зміни парадигми, хоча технології ще не були готові.
Експертні системи, такі як MYCIN (яка діагностувала бактеріальні інфекції) і DENDRAL (яка ідентифікувала хімічні сполуки), організовували інформацію в структурованих базах знань і використовували механізми логічного висновку, щоб робити висновки. У застосуванні до розмовних інтерфейсів цей підхід дозволив чат-ботам перейти від простого зіставлення шаблонів до чогось схожого на міркування – принаймні у вузьких доменах.
Компанії почали впроваджувати такі практичні програми, як автоматизовані системи обслуговування клієнтів, використовуючи цю технологію. Ці системи зазвичай використовували дерева рішень і взаємодію на основі меню, а не бесіду у вільній формі, але вони являли собою перші спроби автоматизувати взаємодії, які раніше вимагали втручання людини.
Обмеження залишалися значними. Ці системи були крихкими, нездатними витончено обробляти несподівані вхідні дані. Вони вимагали величезних зусиль від інженерів знань, щоб вручну закодувати інформацію та правила. І, можливо, найголовніше, вони все ще не могли по-справжньому зрозуміти природну мову в її повній складності та неоднозначності.
Тим не менш, ця епоха встановила важливі концепції, які пізніше стануть вирішальними для сучасного розмовного ШІ: структуроване представлення знань, логічний висновок і спеціалізація домену. Сцена готувалася для зміни парадигми, хоча технології ще не були готові.
Розуміння природної мови: прорив у комп’ютерній лінгвістиці
Кінець 1990-х і початок 2000-х привернули увагу до обробки природної мови (NLP) і комп’ютерної лінгвістики. Замість того, щоб намагатися вручну закодувати правила для всіх можливих взаємодій, дослідники почали розробляти статистичні методи, щоб допомогти комп’ютерам зрозуміти закономірності, властиві людській мові.
Цю зміну сприяли кілька факторів: збільшення обчислювальної потужності, кращі алгоритми та, що важливо, доступність великих текстових корпусів, які можна аналізувати для виявлення лінгвістичних шаблонів. Системи почали включати такі методи, як:
Позначення частин мови: визначення того, чи функціонують слова як іменники, дієслова, прикметники тощо.
Розпізнавання іменованих сутностей: виявлення та класифікація власних імен (людей, організацій, місць).
Аналіз настроїв: Визначення емоційної тональності тексту.
Синтаксичний аналіз: Аналіз структури речення для виявлення граматичних зв’язків між словами.
Один помітний прорив стався з Watson від IBM, який знаменито переміг людей-чемпіонів у вікторині Jeopardy! у 2011 році. Хоча Watson не є суто розмовною системою, вона продемонструвала безпрецедентні здібності розуміти питання природною мовою, здійснювати пошук у величезних сховищах знань і формулювати відповіді – можливості, які виявляться важливими для наступного покоління чат-ботів.
Незабаром з'явилися комерційні програми. Siri від Apple була запущена в 2011 році, надавши розмовні інтерфейси звичайним споживачам. Незважаючи на те, що Siri обмежена за сучасними стандартами, вона стала значним прогресом у тому, щоб зробити помічників ШІ доступними для звичайних користувачів. Cortana від Microsoft, Assistant від Google і Alexa від Amazon з’являться за ними, кожен з яких просуватиме сучасні розмовні штучні інтелекту для споживачів.
Незважаючи на ці досягнення, системам цієї епохи все ще було важко з контекстом, міркуваннями здорового глузду та генерацією справді природних відповідей. Вони були більш досвідченими, ніж їхні пращури, які керувалися правилами, але залишалися принципово обмеженими у своєму розумінні мови та світу.
Цю зміну сприяли кілька факторів: збільшення обчислювальної потужності, кращі алгоритми та, що важливо, доступність великих текстових корпусів, які можна аналізувати для виявлення лінгвістичних шаблонів. Системи почали включати такі методи, як:
Позначення частин мови: визначення того, чи функціонують слова як іменники, дієслова, прикметники тощо.
Розпізнавання іменованих сутностей: виявлення та класифікація власних імен (людей, організацій, місць).
Аналіз настроїв: Визначення емоційної тональності тексту.
Синтаксичний аналіз: Аналіз структури речення для виявлення граматичних зв’язків між словами.
Один помітний прорив стався з Watson від IBM, який знаменито переміг людей-чемпіонів у вікторині Jeopardy! у 2011 році. Хоча Watson не є суто розмовною системою, вона продемонструвала безпрецедентні здібності розуміти питання природною мовою, здійснювати пошук у величезних сховищах знань і формулювати відповіді – можливості, які виявляться важливими для наступного покоління чат-ботів.
Незабаром з'явилися комерційні програми. Siri від Apple була запущена в 2011 році, надавши розмовні інтерфейси звичайним споживачам. Незважаючи на те, що Siri обмежена за сучасними стандартами, вона стала значним прогресом у тому, щоб зробити помічників ШІ доступними для звичайних користувачів. Cortana від Microsoft, Assistant від Google і Alexa від Amazon з’являться за ними, кожен з яких просуватиме сучасні розмовні штучні інтелекту для споживачів.
Незважаючи на ці досягнення, системам цієї епохи все ще було важко з контекстом, міркуваннями здорового глузду та генерацією справді природних відповідей. Вони були більш досвідченими, ніж їхні пращури, які керувалися правилами, але залишалися принципово обмеженими у своєму розумінні мови та світу.
Машинне навчання та підхід, керований даними
Середина 2010-х ознаменувала ще одну зміну парадигми розмовного ШІ з широким впровадженням методів машинного навчання. Замість того, щоб покладатися на створені вручну правила чи обмежені статистичні моделі, інженери почали створювати системи, які можуть вивчати шаблони безпосередньо з даних – і багато з них.
Ця епоха побачила зростання класифікації намірів і вилучення сутностей як основних компонентів розмовної архітектури. Коли користувач робив запит, система:
Класифікуйте загальний намір (наприклад, бронювання авіаквитка, перевірка погоди, відтворення музики)
Витягніть відповідні сутності (наприклад, місця, дати, назви пісень)
Зіставте їх із конкретними діями чи відповідями
Запуск Facebook (нині Meta) своєї платформи Messenger у 2016 році дозволив розробникам створювати чат-боти, які могли б охопити мільйони користувачів, викликавши хвилю комерційного інтересу. Багато компаній поспішили запровадити чат-ботів, хоча результати були неоднозначними. Ранні комерційні впровадження часто розчаровували користувачів через обмежене розуміння та жорсткі потоки розмов.
У цей період також розвивалася технічна архітектура розмовних систем. Типовий підхід передбачав конвеєр спеціалізованих компонентів:
Автоматичне розпізнавання мовлення (для голосових інтерфейсів)
Розуміння природної мови
Управління діалогом
Генерація природної мови
Синтез мовлення (для голосових інтерфейсів)
Кожен компонент можна оптимізувати окремо, дозволяючи поступові вдосконалення. Однак ці архітектури конвеєрів іноді страждали від розповсюдження помилок – помилки на ранніх стадіях каскадом поширювалися по системі.
Хоча машинне навчання значно покращило можливості, системам все ще було важко підтримувати контекст під час довгих розмов, розуміти неявну інформацію та генерувати справді різноманітні та природні відповіді. Наступний прорив вимагав би більш радикального підходу.
Ця епоха побачила зростання класифікації намірів і вилучення сутностей як основних компонентів розмовної архітектури. Коли користувач робив запит, система:
Класифікуйте загальний намір (наприклад, бронювання авіаквитка, перевірка погоди, відтворення музики)
Витягніть відповідні сутності (наприклад, місця, дати, назви пісень)
Зіставте їх із конкретними діями чи відповідями
Запуск Facebook (нині Meta) своєї платформи Messenger у 2016 році дозволив розробникам створювати чат-боти, які могли б охопити мільйони користувачів, викликавши хвилю комерційного інтересу. Багато компаній поспішили запровадити чат-ботів, хоча результати були неоднозначними. Ранні комерційні впровадження часто розчаровували користувачів через обмежене розуміння та жорсткі потоки розмов.
У цей період також розвивалася технічна архітектура розмовних систем. Типовий підхід передбачав конвеєр спеціалізованих компонентів:
Автоматичне розпізнавання мовлення (для голосових інтерфейсів)
Розуміння природної мови
Управління діалогом
Генерація природної мови
Синтез мовлення (для голосових інтерфейсів)
Кожен компонент можна оптимізувати окремо, дозволяючи поступові вдосконалення. Однак ці архітектури конвеєрів іноді страждали від розповсюдження помилок – помилки на ранніх стадіях каскадом поширювалися по системі.
Хоча машинне навчання значно покращило можливості, системам все ще було важко підтримувати контекст під час довгих розмов, розуміти неявну інформацію та генерувати справді різноманітні та природні відповіді. Наступний прорив вимагав би більш радикального підходу.
Революція трансформаторів: моделі нейронної мови
2017 рік став переломним моментом в історії штучного інтелекту з публікацією книги «Увага — це все, що вам потрібно», у якій представлено архітектуру Transformer, яка здійснить революцію в обробці природної мови. На відміну від попередніх підходів, які обробляли текст послідовно, Transformers могли розглядати весь уривок одночасно, дозволяючи їм краще фіксувати зв’язки між словами незалежно від їх відстані одне від одного.
Ця інновація уможливила розробку дедалі потужніших мовних моделей. У 2018 році Google представила BERT (Bidirectional Encoder Representations from Transformers), який значно підвищив ефективність виконання різних завдань із розуміння мови. У 2019 році OpenAI випустив GPT-2, продемонструвавши безпрецедентні можливості генерації зв’язного, контекстуально релевантного тексту.
Найбільш драматичний стрибок стався у 2020 році з GPT-3, масштабування до 175 мільярдів параметрів (порівняно з 1,5 мільярдами GPT-2). Це величезне збільшення масштабу в поєднанні з архітектурними вдосконаленнями створило якісно інші можливості. GPT-3 міг генерувати дивовижно схожий на людину текст, розуміти контекст у тисячах слів і навіть виконувати завдання, яким його явно не навчали.
Для розмовного штучного інтелекту ці досягнення переведено на чат-ботів, які можуть:
Підтримуйте зв'язну розмову протягом багатьох оборотів
Розумійте нюанси запитів без явного навчання
Створюйте різноманітні, відповідні контексту відповіді
Адаптуйте їх тон і стиль відповідно до користувача
Вирішуйте неясність і пояснюйте, коли це необхідно
Випуск ChatGPT наприкінці 2022 року зробив ці можливості популярними, залучивши більше мільйона користувачів за кілька днів після запуску. Раптом широка громадськість отримала доступ до розмовного ШІ, який, здавалося, якісно відрізнявся від усього, що було раніше – більш гнучким, більш обізнаним і більш природним у своїй взаємодії.
Швидко пішли комерційні впровадження, коли компанії включили великі мовні моделі у свої платформи обслуговування клієнтів, інструменти створення вмісту та програми для продуктивності. Швидке впровадження відобразило як технологічний стрибок, так і інтуїтивно зрозумілий інтерфейс, який забезпечували ці моделі – зрештою, розмова є найприроднішим способом спілкування між людьми.
Ця інновація уможливила розробку дедалі потужніших мовних моделей. У 2018 році Google представила BERT (Bidirectional Encoder Representations from Transformers), який значно підвищив ефективність виконання різних завдань із розуміння мови. У 2019 році OpenAI випустив GPT-2, продемонструвавши безпрецедентні можливості генерації зв’язного, контекстуально релевантного тексту.
Найбільш драматичний стрибок стався у 2020 році з GPT-3, масштабування до 175 мільярдів параметрів (порівняно з 1,5 мільярдами GPT-2). Це величезне збільшення масштабу в поєднанні з архітектурними вдосконаленнями створило якісно інші можливості. GPT-3 міг генерувати дивовижно схожий на людину текст, розуміти контекст у тисячах слів і навіть виконувати завдання, яким його явно не навчали.
Для розмовного штучного інтелекту ці досягнення переведено на чат-ботів, які можуть:
Підтримуйте зв'язну розмову протягом багатьох оборотів
Розумійте нюанси запитів без явного навчання
Створюйте різноманітні, відповідні контексту відповіді
Адаптуйте їх тон і стиль відповідно до користувача
Вирішуйте неясність і пояснюйте, коли це необхідно
Випуск ChatGPT наприкінці 2022 року зробив ці можливості популярними, залучивши більше мільйона користувачів за кілька днів після запуску. Раптом широка громадськість отримала доступ до розмовного ШІ, який, здавалося, якісно відрізнявся від усього, що було раніше – більш гнучким, більш обізнаним і більш природним у своїй взаємодії.
Швидко пішли комерційні впровадження, коли компанії включили великі мовні моделі у свої платформи обслуговування клієнтів, інструменти створення вмісту та програми для продуктивності. Швидке впровадження відобразило як технологічний стрибок, так і інтуїтивно зрозумілий інтерфейс, який забезпечували ці моделі – зрештою, розмова є найприроднішим способом спілкування між людьми.
Протестуйте ШІ на ВАШОМУ веб-сайті за 60 секунд
Подивіться, як наш штучний інтелект миттєво аналізує ваш веб-сайт і створює персоналізованого чат-бота - без реєстрації. Просто введіть свою URL-адресу та спостерігайте, як це працює!
Готово за 60 секунд
Не потрібно програмування
100% безпечно
Мультимодальні можливості: крім текстових розмов
У той час як текст домінував у розробці розмовного штучного інтелекту, останніми роками спостерігався поштовх до мультимодальних систем, які можуть розуміти та генерувати кілька типів медіа. Ця еволюція відображає фундаментальну істину про людське спілкування – ми не просто використовуємо слова; ми жестикулюємо, показуємо зображення, малюємо діаграми та використовуємо наше середовище, щоб передати значення.
Моделі візуальної мови, як-от DALL-E, Midjourney і Stable Diffusion, продемонстрували здатність генерувати зображення з текстових описів, тоді як моделі, такі як GPT-4 із візуальними можливостями, могли аналізувати зображення та обговорювати їх розумно. Це відкрило нові можливості для розмовних інтерфейсів:
Боти обслуговування клієнтів, які можуть аналізувати фотографії пошкоджених продуктів
Помічники покупців, які можуть ідентифікувати товари на зображеннях і знаходити схожі продукти
Навчальні інструменти, які можуть пояснити діаграми та візуальні поняття
Функції доступності, які можуть описувати зображення для користувачів із вадами зору
Голосові можливості також значно покращилися. Ранні мовні інтерфейси, такі як системи IVR (Interactive Voice Response), були загальновідомими розчаруваннями, обмежені жорсткими командами та структурами меню. Сучасні голосові помічники можуть розуміти природні моделі мовлення, враховувати різні акценти та недоліки мовлення та реагувати синтезованими голосами, що звучать все більш природно.
Поєднання цих можливостей створює справді мультимодальний розмовний штучний інтелект, який може плавно перемикатися між різними режимами спілкування на основі контексту та потреб користувача. Користувач може почати з текстового запитання про ремонт свого принтера, надіслати фотографію повідомлення про помилку, отримати діаграму з підсвічуванням відповідних кнопок, а потім перейти до голосових інструкцій, поки його руки зайняті ремонтом.
Цей мультимодальний підхід являє собою не лише технічний прогрес, але й фундаментальний зсув до більш природної взаємодії людини з комп’ютером – спілкування з користувачами в будь-якому режимі спілкування, який найкраще підходить для їхнього поточного контексту та потреб.
Моделі візуальної мови, як-от DALL-E, Midjourney і Stable Diffusion, продемонстрували здатність генерувати зображення з текстових описів, тоді як моделі, такі як GPT-4 із візуальними можливостями, могли аналізувати зображення та обговорювати їх розумно. Це відкрило нові можливості для розмовних інтерфейсів:
Боти обслуговування клієнтів, які можуть аналізувати фотографії пошкоджених продуктів
Помічники покупців, які можуть ідентифікувати товари на зображеннях і знаходити схожі продукти
Навчальні інструменти, які можуть пояснити діаграми та візуальні поняття
Функції доступності, які можуть описувати зображення для користувачів із вадами зору
Голосові можливості також значно покращилися. Ранні мовні інтерфейси, такі як системи IVR (Interactive Voice Response), були загальновідомими розчаруваннями, обмежені жорсткими командами та структурами меню. Сучасні голосові помічники можуть розуміти природні моделі мовлення, враховувати різні акценти та недоліки мовлення та реагувати синтезованими голосами, що звучать все більш природно.
Поєднання цих можливостей створює справді мультимодальний розмовний штучний інтелект, який може плавно перемикатися між різними режимами спілкування на основі контексту та потреб користувача. Користувач може почати з текстового запитання про ремонт свого принтера, надіслати фотографію повідомлення про помилку, отримати діаграму з підсвічуванням відповідних кнопок, а потім перейти до голосових інструкцій, поки його руки зайняті ремонтом.
Цей мультимодальний підхід являє собою не лише технічний прогрес, але й фундаментальний зсув до більш природної взаємодії людини з комп’ютером – спілкування з користувачами в будь-якому режимі спілкування, який найкраще підходить для їхнього поточного контексту та потреб.
Пошуково-доповнена генерація: основа ШІ на фактах
Незважаючи на свої вражаючі можливості, великі мовні моделі мають властиві обмеження. Вони можуть «галюцинувати» інформацію, впевнено викладаючи правдоподібні, але неправдиві факти. Їхні знання обмежуються тим, що було в їхніх навчальних даних, створюючи граничну дату знання. І їм не вистачає можливості доступу до інформації в реальному часі або спеціалізованих баз даних, якщо вони спеціально не розроблені для цього.
Як вирішення цих проблем з’явилася генерація з доповненим пошуком (RAG). Замість того, щоб покладатися виключно на параметри, отримані під час навчання, системи RAG поєднують генеративні можливості мовних моделей із механізмами пошуку, які можуть отримати доступ до зовнішніх джерел знань.
Типова архітектура RAG працює так:
Система отримує запит користувача
Він шукає інформацію, що стосується запиту, у відповідних базах знань
Він передає як запит, так і отриману інформацію в мовну модель
Модель генерує відповідь, засновану на отриманих фактах
Цей підхід має кілька переваг:
Більш точні, фактичні відповіді шляхом обґрунтування генерації перевіреної інформації
Можливість доступу до актуальної інформації поза межами навчання моделі
Спеціальні знання з предметних джерел, як-от документація компанії
Прозорість та посилання на джерела інформації
Для підприємств, які впроваджують розмовний штучний інтелект, RAG виявився особливо цінним для програм обслуговування клієнтів. Банківський чат-бот, наприклад, може отримати доступ до найновіших документів політики, інформації про рахунки та записів транзакцій, щоб надавати точні персоналізовані відповіді, які були б неможливі за автономної мовної моделі.
Еволюція систем RAG продовжується з підвищенням точності пошуку, більш складними методами інтеграції отриманої інформації зі згенерованим текстом і кращими механізмами для оцінки надійності різних джерел інформації.
Як вирішення цих проблем з’явилася генерація з доповненим пошуком (RAG). Замість того, щоб покладатися виключно на параметри, отримані під час навчання, системи RAG поєднують генеративні можливості мовних моделей із механізмами пошуку, які можуть отримати доступ до зовнішніх джерел знань.
Типова архітектура RAG працює так:
Система отримує запит користувача
Він шукає інформацію, що стосується запиту, у відповідних базах знань
Він передає як запит, так і отриману інформацію в мовну модель
Модель генерує відповідь, засновану на отриманих фактах
Цей підхід має кілька переваг:
Більш точні, фактичні відповіді шляхом обґрунтування генерації перевіреної інформації
Можливість доступу до актуальної інформації поза межами навчання моделі
Спеціальні знання з предметних джерел, як-от документація компанії
Прозорість та посилання на джерела інформації
Для підприємств, які впроваджують розмовний штучний інтелект, RAG виявився особливо цінним для програм обслуговування клієнтів. Банківський чат-бот, наприклад, може отримати доступ до найновіших документів політики, інформації про рахунки та записів транзакцій, щоб надавати точні персоналізовані відповіді, які були б неможливі за автономної мовної моделі.
Еволюція систем RAG продовжується з підвищенням точності пошуку, більш складними методами інтеграції отриманої інформації зі згенерованим текстом і кращими механізмами для оцінки надійності різних джерел інформації.
Модель співпраці людини та ШІ: пошук правильного балансу
У міру розширення можливостей розмовного ШІ відносини між людьми та системами ШІ розвивалися. Ранні чат-боти чітко позиціонувалися як інструменти – обмежені за обсягом і явно нелюдські у їхній взаємодії. Сучасні системи стирають ці межі, створюючи нові питання про те, як розробити ефективну співпрацю людини та ШІ.
Найуспішніші впровадження сьогодні реалізуються за моделлю співпраці, де:
AI обробляє рутинні повторювані запити, які не вимагають оцінки людини
Люди зосереджуються на складних випадках, які потребують співчуття, етичних міркувань або творчого вирішення проблем
Система знає свої обмеження та плавно переходить до людей, коли це необхідно
Перехід між штучним інтелектом і людською підтримкою відбувається легко для користувача
Агенти-люди мають повний контекст історії розмов із ШІ
ШІ продовжує вчитися на людському втручанні, поступово розширюючи свої можливості
Цей підхід визнає, що розмовний штучний інтелект не повинен прагнути повністю замінити людську взаємодію, а скоріше доповнювати її, обробляючи великі обсяги простих запитів, які забирають час людей-агентів, забезпечуючи при цьому складні питання, які досягають потрібної людини.
Реалізація цієї моделі відрізняється в різних галузях. У сфері охорони здоров’я чат-боти штучного інтелекту можуть займатися плануванням зустрічей і базовим скринінгом симптомів, забезпечуючи при цьому медичну консультацію від кваліфікованих спеціалістів. У юридичних послугах штучний інтелект може допомогти з підготовкою документів і дослідженням, залишаючи тлумачення та стратегію адвокатам. У сфері обслуговування клієнтів штучний інтелект може вирішувати типові проблеми, одночасно направляючи складні проблеми спеціалізованим агентам.
Оскільки можливості штучного інтелекту продовжують розвиватися, межа між тим, що вимагає участі людини, і тим, що можна автоматизувати, буде зміщуватися, але фундаментальний принцип залишається: ефективний розмовний штучний інтелект повинен покращувати людські можливості, а не просто замінювати їх.
Найуспішніші впровадження сьогодні реалізуються за моделлю співпраці, де:
AI обробляє рутинні повторювані запити, які не вимагають оцінки людини
Люди зосереджуються на складних випадках, які потребують співчуття, етичних міркувань або творчого вирішення проблем
Система знає свої обмеження та плавно переходить до людей, коли це необхідно
Перехід між штучним інтелектом і людською підтримкою відбувається легко для користувача
Агенти-люди мають повний контекст історії розмов із ШІ
ШІ продовжує вчитися на людському втручанні, поступово розширюючи свої можливості
Цей підхід визнає, що розмовний штучний інтелект не повинен прагнути повністю замінити людську взаємодію, а скоріше доповнювати її, обробляючи великі обсяги простих запитів, які забирають час людей-агентів, забезпечуючи при цьому складні питання, які досягають потрібної людини.
Реалізація цієї моделі відрізняється в різних галузях. У сфері охорони здоров’я чат-боти штучного інтелекту можуть займатися плануванням зустрічей і базовим скринінгом симптомів, забезпечуючи при цьому медичну консультацію від кваліфікованих спеціалістів. У юридичних послугах штучний інтелект може допомогти з підготовкою документів і дослідженням, залишаючи тлумачення та стратегію адвокатам. У сфері обслуговування клієнтів штучний інтелект може вирішувати типові проблеми, одночасно направляючи складні проблеми спеціалізованим агентам.
Оскільки можливості штучного інтелекту продовжують розвиватися, межа між тим, що вимагає участі людини, і тим, що можна автоматизувати, буде зміщуватися, але фундаментальний принцип залишається: ефективний розмовний штучний інтелект повинен покращувати людські можливості, а не просто замінювати їх.
Пейзаж майбутнього: куди рухається розмовний ШІ
Коли ми дивимося на горизонт, кілька нових тенденцій формують майбутнє розмовного ШІ. Ці розробки обіцяють не лише поступові покращення, але й потенційно трансформаційні зміни в тому, як ми взаємодіємо з технологіями.
Масштабна персоналізація: майбутні системи дедалі більше пристосовуватимуть свої реакції не лише до безпосереднього контексту, але й до стилю спілкування, уподобань, рівня знань та історії стосунків кожного користувача. Ця персоналізація зробить взаємодію більш природною та актуальною, хоча вона піднімає важливі питання щодо конфіденційності та використання даних.
Емоційний інтелект. У той час як сучасні системи можуть виявляти базові настрої, майбутній розмовний ШІ розвине більш складний емоційний інтелект – розпізнавання тонких емоційних станів, належне реагування на страждання чи розчарування та відповідне адаптування свого тону та підходу. Ця можливість буде особливо цінною для обслуговування клієнтів, охорони здоров’я та освіти.
Проактивна допомога: Замість того, щоб чекати явних запитів, розмовні системи нового покоління передбачатимуть потреби на основі контексту, історії користувача та сигналів навколишнього середовища. Система може помітити, що ви плануєте кілька зустрічей у незнайомому місті, і заздалегідь запропонувати варіанти транспорту або прогноз погоди.
Безперебійна мультимодальна інтеграція: майбутні системи перейдуть від простої підтримки різних модальностей до їх безпроблемної інтеграції. Розмова може текти природно між текстом, голосом, зображеннями та інтерактивними елементами, вибираючи правильну модальність для кожної частини інформації, не вимагаючи явного вибору користувача.
Спеціалізовані експерти в галузі: хоча помічники загального призначення продовжуватимуть удосконалюватися, ми також побачимо розвиток вузькоспеціалізованого розмовного ШІ з глибоким досвідом у конкретних сферах – помічники юристів, які розуміють прецедентне право та прецеденти, медичні системи з всебічними знаннями про взаємодію ліків і протоколи лікування, або фінансові консультанти, обізнані з податковими кодексами та інвестиційними стратегіями.
По-справжньому безперервне навчання. Майбутні системи переходитимуть від періодичного перенавчання до безперервного навчання на основі взаємодії, з часом станучи більш корисними та персоналізованими, зберігаючи відповідні гарантії конфіденційності.
Незважаючи на ці захоплюючі можливості, проблеми залишаються. Занепокоєння щодо конфіденційності, пом’якшення упередженості, відповідна прозорість і встановлення належного рівня людського нагляду є постійними проблемами, які впливатимуть як на технологію, так і на її регулювання. Найуспішнішими впровадженнями будуть ті, які продумано вирішують ці проблеми, водночас забезпечуючи справжню цінність для користувачів.
Очевидно лише те, що розмовний штучний інтелект перейшов від нішевої технології до основної парадигми інтерфейсу, яка все більше буде посередником нашої взаємодії з цифровими системами. Еволюційний шлях від простого зіставлення шаблонів ELIZA до сучасних складних мовних моделей є одним із найважливіших досягнень у взаємодії людини з комп’ютером – і ця подорож ще далека від завершення.
Масштабна персоналізація: майбутні системи дедалі більше пристосовуватимуть свої реакції не лише до безпосереднього контексту, але й до стилю спілкування, уподобань, рівня знань та історії стосунків кожного користувача. Ця персоналізація зробить взаємодію більш природною та актуальною, хоча вона піднімає важливі питання щодо конфіденційності та використання даних.
Емоційний інтелект. У той час як сучасні системи можуть виявляти базові настрої, майбутній розмовний ШІ розвине більш складний емоційний інтелект – розпізнавання тонких емоційних станів, належне реагування на страждання чи розчарування та відповідне адаптування свого тону та підходу. Ця можливість буде особливо цінною для обслуговування клієнтів, охорони здоров’я та освіти.
Проактивна допомога: Замість того, щоб чекати явних запитів, розмовні системи нового покоління передбачатимуть потреби на основі контексту, історії користувача та сигналів навколишнього середовища. Система може помітити, що ви плануєте кілька зустрічей у незнайомому місті, і заздалегідь запропонувати варіанти транспорту або прогноз погоди.
Безперебійна мультимодальна інтеграція: майбутні системи перейдуть від простої підтримки різних модальностей до їх безпроблемної інтеграції. Розмова може текти природно між текстом, голосом, зображеннями та інтерактивними елементами, вибираючи правильну модальність для кожної частини інформації, не вимагаючи явного вибору користувача.
Спеціалізовані експерти в галузі: хоча помічники загального призначення продовжуватимуть удосконалюватися, ми також побачимо розвиток вузькоспеціалізованого розмовного ШІ з глибоким досвідом у конкретних сферах – помічники юристів, які розуміють прецедентне право та прецеденти, медичні системи з всебічними знаннями про взаємодію ліків і протоколи лікування, або фінансові консультанти, обізнані з податковими кодексами та інвестиційними стратегіями.
По-справжньому безперервне навчання. Майбутні системи переходитимуть від періодичного перенавчання до безперервного навчання на основі взаємодії, з часом станучи більш корисними та персоналізованими, зберігаючи відповідні гарантії конфіденційності.
Незважаючи на ці захоплюючі можливості, проблеми залишаються. Занепокоєння щодо конфіденційності, пом’якшення упередженості, відповідна прозорість і встановлення належного рівня людського нагляду є постійними проблемами, які впливатимуть як на технологію, так і на її регулювання. Найуспішнішими впровадженнями будуть ті, які продумано вирішують ці проблеми, водночас забезпечуючи справжню цінність для користувачів.
Очевидно лише те, що розмовний штучний інтелект перейшов від нішевої технології до основної парадигми інтерфейсу, яка все більше буде посередником нашої взаємодії з цифровими системами. Еволюційний шлях від простого зіставлення шаблонів ELIZA до сучасних складних мовних моделей є одним із найважливіших досягнень у взаємодії людини з комп’ютером – і ця подорож ще далека від завершення.





