РҹСҖРҫСӮРөСҒСӮСғР№СӮРө Р’РҗРЁ БізРҪРөСҒ Р·Р° РҘвилиРҪ
РЎСӮРІРҫСҖС–СӮСҢ РҫРұліРәРҫРІРёР№ Р·Р°РҝРёСҒ С– Р·Р°РҝСғСҒСӮС–СӮСҢ СҒРІРҫРіРҫ AI-СҮР°СӮРұРҫСӮР° Р·Р° ліСҮРөРҪС– хвилиРҪРё. РҹРҫРІРҪС–СҒСӮСҺ РҪалаСҲСӮРҫРІСғС”СӮСҢСҒСҸ, РұРөР· РҪРөРҫРұС…С–РҙРҪРҫСҒСӮС– РәРҫРҙСғРІР°РҪРҪСҸ - РҝРҫСҮРҪС–СӮСҢ залСғСҮР°СӮРё СҒРІРҫС—С… РәлієРҪСӮС–РІ РјРёСӮСӮєвРҫ!
Р“РҫСӮРҫРІРҫ Р·Р° хвилиРҪРё
Р‘РөР· РҝСҖРҫРіСҖамСғРІР°РҪРҪСҸ
100% РұРөР·РҝРөСҮРҪРҫ
РЎРәСҖРҫРјРҪРёР№ РҝРҫСҮР°СӮРҫРә: СҖР°РҪРҪС– СҒРёСҒСӮРөРјРё, Р·Р°СҒРҪРҫРІР°РҪС– РҪР° РҝСҖавилах
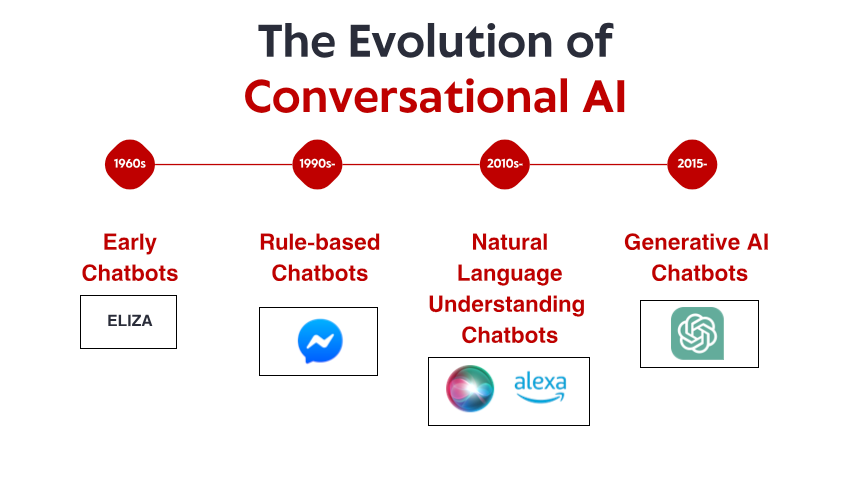
РҶСҒСӮРҫСҖС–СҸ СҖРҫР·РјРҫРІРҪРҫРіРҫ СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ РҝРҫСҮРёРҪаєСӮСҢСҒСҸ РІ 1960-С… СҖРҫРәах, Р·Р°РҙРҫРІРіРҫ РҙРҫ СӮРҫРіРҫ, СҸРә СҒРјР°СҖСӮС„РҫРҪРё СӮР° РіРҫР»РҫСҒРҫРІС– РҝРҫРјС–СҮРҪРёРәРё СҒСӮали РҝСҖРөРҙРјРөСӮами РҝРөСҖСҲРҫС— РҪРөРҫРұС…С–РҙРҪРҫСҒСӮС–. РЈ РҪРөРІРөлиРәС–Р№ лаРұРҫСҖР°СӮРҫСҖС–С— РңР°СҒСҒР°СҮСғСҒРөСӮСҒСҢРәРҫРіРҫ СӮРөС…РҪРҫР»РҫРіС–СҮРҪРҫРіРҫ С–РҪСҒСӮРёСӮСғСӮСғ РәРҫРјРҝ'СҺСӮРөСҖРҪРёР№ РІСҮРөРҪРёР№ ДжРҫР·РөС„ ВайСҶРөРҪРұР°СғРј СҒСӮРІРҫСҖРёРІ СӮРө, СүРҫ РұагаСӮРҫ С…СӮРҫ вважає РҝРөСҖСҲРёРј СҮР°СӮ-РұРҫСӮРҫРј: ELIZA. Р РҫР·СҖРҫРұР»РөРҪРёР№ РҙР»СҸ С–РјС–СӮР°СҶС–С— РҝСҒРёС…РҫСӮРөСҖР°РҝРөРІСӮР°-СҖРҫРҙР¶РөСҖС–Р°РҪСҶР°, ELIZA РҝСҖР°СҶСҺвала Р·Р° РҙРҫРҝРҫРјРҫРіРҫСҺ РҝСҖРҫСҒСӮРёС… РҝСҖавил Р·С–СҒСӮавлРөРҪРҪСҸ Р·С– Р·СҖазРәами СӮР° заміСүРөРҪРҪСҸ. РҡРҫли РәРҫСҖРёСҒСӮСғРІР°СҮ РҙСҖСғРәСғвав В«РңРөРҪС– СҒСғРјРҪРҫВ», ELIZA РјРҫгла РІС–РҙРҝРҫРІС–СҒСӮРё «ЧРҫРјСғ СӮРҫРұС– СҒСғРјРҪРҫ?В» вҖ“ СҒСӮРІРҫСҖСҺСҺСҮРё С–Р»СҺР·С–СҺ СҖРҫР·СғРјС–РҪРҪСҸ, РҝРөСҖРөС„РҫСҖРјСғР»СҺвавСҲРё СӮРІРөСҖРҙР¶РөРҪРҪСҸ СҸРә РҝРёСӮР°РҪРҪСҸ.
ELIZA РұСғла РІРёР·РҪР°СҮРҪРҫСҺ РҪРө СҒРІРҫС”СҺ СӮРөС…РҪС–СҮРҪРҫСҺ РҙРҫСҒРәРҫРҪаліСҒСӮСҺ вҖ“ Р·Р° СҒСғСҮР°СҒРҪРёРјРё СҒСӮР°РҪРҙР°СҖСӮами РҝСҖРҫРіСҖама РұСғла РҪРөР№РјРҫРІС–СҖРҪРҫ РҝСҖРҫСҒСӮРҫСҺ. РЁРІРёРҙСҲРө, СҶРө РұСғРІ глиРұРҫРәРёР№ РІРҝлив, СҸРәРёР№ РІРҫРҪР° мала РҪР° РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ. РқРөзважаСҺСҮРё РҪР° СӮРө, СүРҫ РІРҫРҪРё Р·РҪали, СүРҫ СҖРҫР·РјРҫРІР»СҸСҺСӮСҢ Р· РәРҫРјРҝ'СҺСӮРөСҖРҪРҫСҺ РҝСҖРҫРіСҖамРҫСҺ, СҸРәР° РҪР°СҒРҝСҖавРҙС– РҪС–СҮРҫРіРҫ РҪРө СҖРҫР·СғРјС–С”, РұагаСӮРҫ Р»СҺРҙРөР№ РІСҒСӮР°РҪРҫРІР»СҺвали РөРјРҫСҶС–Р№РҪС– Р·РІ'СҸР·РәРё Р· ELIZA, РҙС–Р»СҸСҮРёСҒСҢ глиРұРҫРәРҫ РҫСҒРҫРұРёСҒСӮРёРјРё РҙСғРјРәами СӮР° РҝРҫСҮСғСӮСӮСҸРјРё. РҰРө СҸРІРёСүРө, СҸРәРө СҒам ВайСҶРөРҪРұР°СғРј вважав СӮСҖРёРІРҫР¶РҪРёРј, РІРёСҸРІРёР»Рҫ СүРҫСҒСҢ С„СғРҪРҙамРөРҪСӮалСҢРҪРө РҝСҖРҫ Р»СҺРҙСҒСҢРәСғ РҝСҒРёС…РҫР»РҫРіС–СҺ СӮР° РҪР°СҲСғ РіРҫСӮРҫРІРҪС–СҒСӮСҢ Р°РҪСӮСҖРҫРҝРҫРјРҫСҖфізСғРІР°СӮРё РҪавіСӮСҢ РҪайРҝСҖРҫСҒСӮС–СҲС– СҖРҫР·РјРҫРІРҪС– С–РҪСӮРөСҖС„РөР№СҒРё.
РҹСҖРҫСӮСҸРіРҫРј 1970-С… С– 1980-С… СҖРҫРәС–РІ СҮР°СӮ-РұРҫСӮРё РҪР° РҫСҒРҪРҫРІС– РҝСҖавил СҒліРҙСғвали СҲР°РұР»РҫРҪСғ ELIZA Р· РҝРҫСҒСӮСғРҝРҫРІРёРјРё РІРҙРҫСҒРәРҫРҪалРөРҪРҪСҸРјРё. РўР°РәС– РҝСҖРҫРіСҖами, СҸРә PARRY (СүРҫ СҒРёРјСғР»СҺС” РҝР°СҖР°РҪРҫС—РҙалСҢРҪРҫРіРҫ СҲРёР·РҫС„СҖРөРҪС–РәР°) СӮР° RACTER (СҸРәР° В«СҒСӮала авСӮРҫСҖРҫРјВ» РәРҪРёРіРё РҝС–Рҙ РҪазвРҫСҺ «БРҫСҖРҫРҙР° РҝРҫліСҶРөР№СҒСҢРәРҫРіРҫ РҪР°РҝРҫР»РҫРІРёРҪСғ СҒРәРҫРҪСҒСӮСҖСғР№РҫРІР°РҪа»), СӮРІРөСҖРҙРҫ залиСҲалиСҒСҸ РІ СҖамРәах РҝР°СҖР°РҙРёРіРјРё, Р·Р°СҒРҪРҫРІР°РҪРҫС— РҪР° РҝСҖавилах, РІРёРәРҫСҖРёСҒСӮРҫРІСғСҺСҮРё РҝРҫРҝРөСҖРөРҙРҪСҢРҫ РІРёР·РҪР°СҮРөРҪС– СҲР°РұР»РҫРҪРё, Р·С–СҒСӮавлРөРҪРҪСҸ РәР»СҺСҮРҫРІРёС… СҒлів СӮР° СҲР°РұР»РҫРҪРҪС– РІС–РҙРҝРҫРІС–РҙС–.
РҰС– СҖР°РҪРҪС– СҒРёСҒСӮРөРјРё мали СҒРөСҖР№РҫР·РҪС– РҫРұРјРөР¶РөРҪРҪСҸ. Р’РҫРҪРё РҪРө РјРҫгли РҪР°СҒРҝСҖавРҙС– СҖРҫР·СғРјС–СӮРё РјРҫРІСғ, РҪавСҮР°СӮРёСҒСҸ РҪР° взаємРҫРҙС–С— Р°РұРҫ Р°РҙР°РҝСӮСғРІР°СӮРёСҒСҸ РҙРҫ РҪРөРҫСҮС–РәСғРІР°РҪРёС… РҙР°РҪРёС…. РҮС…РҪС– Р·РҪР°РҪРҪСҸ РҫРұРјРөР¶СғвалиСҒСҸ СӮРёРјРё РҝСҖавилами, СҸРәС– С—С…РҪС– РҝСҖРҫРіСҖаміСҒСӮРё СҮС–СӮРәРҫ РІРёР·РҪР°СҮили. РҡРҫли РәРҫСҖРёСҒСӮСғРІР°СҮС– РҪРөРјРёРҪСғСҮРө РІРёС…РҫРҙили Р·Р° СҶС– РјРөжі, С–Р»СҺР·С–СҸ С–РҪСӮРөР»РөРәСӮСғ СҲРІРёРҙРәРҫ СҖСғР№РҪСғвалаСҒСҸ, РІРёСҸРІР»СҸСҺСҮРё РјРөС…Р°РҪС–СҮРҪСғ РҝСҖРёСҖРҫРҙСғ, СүРҫ Р»Рөжала РІ РҫСҒРҪРҫРІС–. РқРөзважаСҺСҮРё РҪР° СҶС– РҫРұРјРөР¶РөРҪРҪСҸ, СҶС– РҪРҫРІР°СӮРҫСҖСҒСҢРәС– СҒРёСҒСӮРөРјРё Р·Р°Рәлали С„СғРҪРҙамРөРҪСӮ, РҪР° СҸРәРҫРјСғ РұСғРҙСғвавСҒСҸ РІРөСҒСҢ майРұСғСӮРҪС–Р№ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ.
ELIZA РұСғла РІРёР·РҪР°СҮРҪРҫСҺ РҪРө СҒРІРҫС”СҺ СӮРөС…РҪС–СҮРҪРҫСҺ РҙРҫСҒРәРҫРҪаліСҒСӮСҺ вҖ“ Р·Р° СҒСғСҮР°СҒРҪРёРјРё СҒСӮР°РҪРҙР°СҖСӮами РҝСҖРҫРіСҖама РұСғла РҪРөР№РјРҫРІС–СҖРҪРҫ РҝСҖРҫСҒСӮРҫСҺ. РЁРІРёРҙСҲРө, СҶРө РұСғРІ глиРұРҫРәРёР№ РІРҝлив, СҸРәРёР№ РІРҫРҪР° мала РҪР° РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ. РқРөзважаСҺСҮРё РҪР° СӮРө, СүРҫ РІРҫРҪРё Р·РҪали, СүРҫ СҖРҫР·РјРҫРІР»СҸСҺСӮСҢ Р· РәРҫРјРҝ'СҺСӮРөСҖРҪРҫСҺ РҝСҖРҫРіСҖамРҫСҺ, СҸРәР° РҪР°СҒРҝСҖавРҙС– РҪС–СҮРҫРіРҫ РҪРө СҖРҫР·СғРјС–С”, РұагаСӮРҫ Р»СҺРҙРөР№ РІСҒСӮР°РҪРҫРІР»СҺвали РөРјРҫСҶС–Р№РҪС– Р·РІ'СҸР·РәРё Р· ELIZA, РҙС–Р»СҸСҮРёСҒСҢ глиРұРҫРәРҫ РҫСҒРҫРұРёСҒСӮРёРјРё РҙСғРјРәами СӮР° РҝРҫСҮСғСӮСӮСҸРјРё. РҰРө СҸРІРёСүРө, СҸРәРө СҒам ВайСҶРөРҪРұР°СғРј вважав СӮСҖРёРІРҫР¶РҪРёРј, РІРёСҸРІРёР»Рҫ СүРҫСҒСҢ С„СғРҪРҙамРөРҪСӮалСҢРҪРө РҝСҖРҫ Р»СҺРҙСҒСҢРәСғ РҝСҒРёС…РҫР»РҫРіС–СҺ СӮР° РҪР°СҲСғ РіРҫСӮРҫРІРҪС–СҒСӮСҢ Р°РҪСӮСҖРҫРҝРҫРјРҫСҖфізСғРІР°СӮРё РҪавіСӮСҢ РҪайРҝСҖРҫСҒСӮС–СҲС– СҖРҫР·РјРҫРІРҪС– С–РҪСӮРөСҖС„РөР№СҒРё.
РҹСҖРҫСӮСҸРіРҫРј 1970-С… С– 1980-С… СҖРҫРәС–РІ СҮР°СӮ-РұРҫСӮРё РҪР° РҫСҒРҪРҫРІС– РҝСҖавил СҒліРҙСғвали СҲР°РұР»РҫРҪСғ ELIZA Р· РҝРҫСҒСӮСғРҝРҫРІРёРјРё РІРҙРҫСҒРәРҫРҪалРөРҪРҪСҸРјРё. РўР°РәС– РҝСҖРҫРіСҖами, СҸРә PARRY (СүРҫ СҒРёРјСғР»СҺС” РҝР°СҖР°РҪРҫС—РҙалСҢРҪРҫРіРҫ СҲРёР·РҫС„СҖРөРҪС–РәР°) СӮР° RACTER (СҸРәР° В«СҒСӮала авСӮРҫСҖРҫРјВ» РәРҪРёРіРё РҝС–Рҙ РҪазвРҫСҺ «БРҫСҖРҫРҙР° РҝРҫліСҶРөР№СҒСҢРәРҫРіРҫ РҪР°РҝРҫР»РҫРІРёРҪСғ СҒРәРҫРҪСҒСӮСҖСғР№РҫРІР°РҪа»), СӮРІРөСҖРҙРҫ залиСҲалиСҒСҸ РІ СҖамРәах РҝР°СҖР°РҙРёРіРјРё, Р·Р°СҒРҪРҫРІР°РҪРҫС— РҪР° РҝСҖавилах, РІРёРәРҫСҖРёСҒСӮРҫРІСғСҺСҮРё РҝРҫРҝРөСҖРөРҙРҪСҢРҫ РІРёР·РҪР°СҮРөРҪС– СҲР°РұР»РҫРҪРё, Р·С–СҒСӮавлРөРҪРҪСҸ РәР»СҺСҮРҫРІРёС… СҒлів СӮР° СҲР°РұР»РҫРҪРҪС– РІС–РҙРҝРҫРІС–РҙС–.
РҰС– СҖР°РҪРҪС– СҒРёСҒСӮРөРјРё мали СҒРөСҖР№РҫР·РҪС– РҫРұРјРөР¶РөРҪРҪСҸ. Р’РҫРҪРё РҪРө РјРҫгли РҪР°СҒРҝСҖавРҙС– СҖРҫР·СғРјС–СӮРё РјРҫРІСғ, РҪавСҮР°СӮРёСҒСҸ РҪР° взаємРҫРҙС–С— Р°РұРҫ Р°РҙР°РҝСӮСғРІР°СӮРёСҒСҸ РҙРҫ РҪРөРҫСҮС–РәСғРІР°РҪРёС… РҙР°РҪРёС…. РҮС…РҪС– Р·РҪР°РҪРҪСҸ РҫРұРјРөР¶СғвалиСҒСҸ СӮРёРјРё РҝСҖавилами, СҸРәС– С—С…РҪС– РҝСҖРҫРіСҖаміСҒСӮРё СҮС–СӮРәРҫ РІРёР·РҪР°СҮили. РҡРҫли РәРҫСҖРёСҒСӮСғРІР°СҮС– РҪРөРјРёРҪСғСҮРө РІРёС…РҫРҙили Р·Р° СҶС– РјРөжі, С–Р»СҺР·С–СҸ С–РҪСӮРөР»РөРәСӮСғ СҲРІРёРҙРәРҫ СҖСғР№РҪСғвалаСҒСҸ, РІРёСҸРІР»СҸСҺСҮРё РјРөС…Р°РҪС–СҮРҪСғ РҝСҖРёСҖРҫРҙСғ, СүРҫ Р»Рөжала РІ РҫСҒРҪРҫРІС–. РқРөзважаСҺСҮРё РҪР° СҶС– РҫРұРјРөР¶РөРҪРҪСҸ, СҶС– РҪРҫРІР°СӮРҫСҖСҒСҢРәС– СҒРёСҒСӮРөРјРё Р·Р°Рәлали С„СғРҪРҙамРөРҪСӮ, РҪР° СҸРәРҫРјСғ РұСғРҙСғвавСҒСҸ РІРөСҒСҢ майРұСғСӮРҪС–Р№ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ.
Р РөРІРҫР»СҺСҶС–СҸ Р·РҪР°РҪСҢ: РөРәСҒРҝРөСҖСӮРҪС– СҒРёСҒСӮРөРјРё СӮР° СҒСӮСҖСғРәСӮСғСҖРҫРІР°РҪР° С–РҪС„РҫСҖРјР°СҶС–СҸ
РЈ 1980-С… СӮР° РҪР° РҝРҫСҮР°СӮРәСғ 1990-С… СҖРҫРәС–РІ Р·'СҸвилиСҒСҸ РөРәСҒРҝРөСҖСӮРҪС– СҒРёСҒСӮРөРјРё вҖ“ РҝСҖРҫРіСҖами СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ, СҖРҫР·СҖРҫРұР»РөРҪС– РҙР»СҸ РІРёСҖС–СҲРөРҪРҪСҸ СҒРәлаРҙРҪРёС… РҝСҖРҫРұР»РөРј СҲР»СҸС…РҫРј С–РјС–СӮР°СҶС–С— Р·РҙС–РұРҪРҫСҒСӮРөР№ РөРәСҒРҝРөСҖСӮС–РІ-Р»СҺРҙРөР№ РҙРҫ РҝСҖРёР№РҪСҸСӮСӮСҸ СҖС–СҲРөРҪСҢ Сғ РҝРөРІРҪРёС… галСғР·СҸС…. РҘРҫСҮР° СҶС– СҒРёСҒСӮРөРјРё РҪРө РұСғли РІ РҝРөСҖСҲСғ СҮРөСҖРіСғ СҖРҫР·СҖРҫРұР»РөРҪС– РҙР»СҸ СҖРҫР·РјРҫРІРё, РІРҫРҪРё СҒСӮали важливим РөРІРҫР»СҺСҶС–Р№РҪРёРј РәСҖРҫРәРҫРј РҙР»СҸ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ, РІРҝСҖРҫРІР°РҙР¶СғСҺСҮРё РұС–Р»СҢСҲ СҒРәлаРҙРҪРө РҝСҖРөРҙСҒСӮавлРөРҪРҪСҸ Р·РҪР°РҪСҢ. Р•РәСҒРҝРөСҖСӮРҪС– СҒРёСҒСӮРөРјРё, СӮР°РәС– СҸРә MYCIN (СҸРәР° РҙіагРҪРҫСҒСӮСғвала РұР°РәСӮРөСҖіалСҢРҪС– С–РҪС„РөРәСҶС–С—) СӮР° DENDRAL (СҸРәР° С–РҙРөРҪСӮифіРәСғвала С…С–РјС–СҮРҪС– СҒРҝРҫР»СғРәРё), РҫСҖРіР°РҪС–Р·РҫРІСғвали С–РҪС„РҫСҖРјР°СҶС–СҺ РІ СҒСӮСҖСғРәСӮСғСҖРҫРІР°РҪРёС… Рұазах Р·РҪР°РҪСҢ СӮР° РІРёРәРҫСҖРёСҒСӮРҫРІСғвали РјРөС…Р°РҪС–Р·РјРё Р»РҫРіС–СҮРҪРҫРіРҫ РІРёСҒРҪРҫРІРәСғ РҙР»СҸ С„РҫСҖРјСғР»СҺРІР°РҪРҪСҸ РІРёСҒРҪРҫРІРәС–РІ. Р—Р°СҒСӮРҫСҒРҫРІР°РҪРёР№ РҙРҫ СҖРҫР·РјРҫРІРҪРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ, СҶРөР№ РҝС–РҙС…С–Рҙ РҙРҫР·РІРҫлив СҮР°СӮ-РұРҫСӮам РІРёР№СӮРё Р·Р° СҖамРәРё РҝСҖРҫСҒСӮРҫРіРҫ Р·С–СҒСӮавлРөРҪРҪСҸ Р·С– Р·СҖазРәами СӮР° РҝРөСҖРөР№СӮРё РҙРҫ СҮРҫРіРҫСҒСҢ, СүРҫ РҪагаРҙСғС” РјС–СҖРәСғРІР°РҪРҪСҸ вҖ“ РҝСҖРёРҪаймРҪС– Сғ РІСғР·СҢРәРёС… РҫРұлаСҒСӮСҸС…. РҡРҫРјРҝР°РҪС–С— РҝРҫСҮали РІРҝСҖРҫРІР°РҙР¶СғРІР°СӮРё РҝСҖР°РәСӮРёСҮРҪС– РҝСҖРҫРіСҖами, СӮР°РәС– СҸРә авСӮРҫРјР°СӮРёР·РҫРІР°РҪС– СҒРёСҒСӮРөРјРё РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ, РІРёРәРҫСҖРёСҒСӮРҫРІСғСҺСҮРё СҶСҺ СӮРөС…РҪРҫР»РҫРіС–СҺ. РҰС– СҒРёСҒСӮРөРјРё зазвиСҮай РІРёРәРҫСҖРёСҒСӮРҫРІСғвали РҙРөСҖРөРІР° СҖС–СҲРөРҪСҢ СӮР° взаємРҫРҙС–СҺ РҪР° РҫСҒРҪРҫРІС– РјРөРҪСҺ, Р° РҪРө СҖРҫР·РјРҫРІСғ Сғ РІС–Р»СҢРҪС–Р№ С„РҫСҖРјС–, алРө РІРҫРҪРё СҸРІР»СҸли СҒРҫРұРҫСҺ СҖР°РҪРҪС– СҒРҝСҖРҫРұРё авСӮРҫРјР°СӮРёР·СғРІР°СӮРё взаємРҫРҙС–СҺ, СҸРәР° СҖР°РҪС–СҲРө вимагала РІСӮСҖСғСҮР°РҪРҪСҸ Р»СҺРҙРёРҪРё. РһРұРјРөР¶РөРҪРҪСҸ залиСҲалиСҒСҸ Р·РҪР°СҮРҪРёРјРё. РҰС– СҒРёСҒСӮРөРјРё РұСғли РәСҖРёС…РәРёРјРё, РҪРөР·РҙР°СӮРҪРёРјРё РәРҫСҖРөРәСӮРҪРҫ РҫРұСҖРҫРұР»СҸСӮРё РҪРөРҫСҮС–РәСғРІР°РҪС– РІС…С–РҙРҪС– РҙР°РҪС–. Р’РҫРҪРё вимагали РІРөлиСҮРөР·РҪРёС… Р·СғСҒРёР»СҢ РІС–Рҙ С–РҪР¶РөРҪРөСҖС–РІ Р·РҪР°РҪСҢ РҙР»СҸ СҖСғСҮРҪРҫРіРҫ РәРҫРҙСғРІР°РҪРҪСҸ С–РҪС„РҫСҖРјР°СҶС–С— СӮР° РҝСҖавил. РҶ, РјР°РұСғСӮСҢ, РҪайгРҫР»РҫРІРҪС–СҲРө, РІРҫРҪРё РІСҒРө СүРө РҪРө РјРҫгли РҝРҫ-СҒРҝСҖавжРҪСҢРҫРјСғ Р·СҖРҫР·СғРјС–СӮРё РҝСҖРёСҖРҫРҙРҪСғ РјРҫРІСғ РІ СғСҒС–Р№ С—С— СҒРәлаРҙРҪРҫСҒСӮС– СӮР° РҪРөРҫРҙРҪРҫР·РҪР°СҮРҪРҫСҒСӮС–.
РўРёРј РҪРө РјРөРҪСҲ, СҶСҸ РөРҝРҫС…Р° Р·Р°РәСҖС–Рҝила важливі РәРҫРҪСҶРөРҝСҶС–С—, СҸРәС– Р·РіРҫРҙРҫРј СҒСӮР°РҪСғСӮСҢ РІРёСҖС–СҲалСҢРҪРёРјРё РҙР»СҸ СҒСғСҮР°СҒРҪРҫРіРҫ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ: СҒСӮСҖСғРәСӮСғСҖРҫРІР°РҪРө РҝСҖРөРҙСҒСӮавлРөРҪРҪСҸ Р·РҪР°РҪСҢ, Р»РҫРіС–СҮРҪРёР№ РІРёСҒРҪРҫРІРҫРә СӮР° СҒРҝРөСҶіалізаСҶС–СҸ РҝСҖРөРҙРјРөСӮРҪРҫС— РҫРұлаСҒСӮС–. Р“РҫСӮСғвалаСҒСҸ РҫСҒРҪРҫРІР° РҙР»СҸ Р·РјС–РҪРё РҝР°СҖР°РҙРёРіРјРё, С…РҫСҮР° СӮРөС…РҪРҫР»РҫРіС–С— СүРө РҪРө РұСғли РҝРҫРІРҪС–СҒСӮСҺ РіРҫСӮРҫРІС–.
РўРёРј РҪРө РјРөРҪСҲ, СҶСҸ РөРҝРҫС…Р° Р·Р°РәСҖС–Рҝила важливі РәРҫРҪСҶРөРҝСҶС–С—, СҸРәС– Р·РіРҫРҙРҫРј СҒСӮР°РҪСғСӮСҢ РІРёСҖС–СҲалСҢРҪРёРјРё РҙР»СҸ СҒСғСҮР°СҒРҪРҫРіРҫ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ: СҒСӮСҖСғРәСӮСғСҖРҫРІР°РҪРө РҝСҖРөРҙСҒСӮавлРөРҪРҪСҸ Р·РҪР°РҪСҢ, Р»РҫРіС–СҮРҪРёР№ РІРёСҒРҪРҫРІРҫРә СӮР° СҒРҝРөСҶіалізаСҶС–СҸ РҝСҖРөРҙРјРөСӮРҪРҫС— РҫРұлаСҒСӮС–. Р“РҫСӮСғвалаСҒСҸ РҫСҒРҪРҫРІР° РҙР»СҸ Р·РјС–РҪРё РҝР°СҖР°РҙРёРіРјРё, С…РҫСҮР° СӮРөС…РҪРҫР»РҫРіС–С— СүРө РҪРө РұСғли РҝРҫРІРҪС–СҒСӮСҺ РіРҫСӮРҫРІС–.
Р РҫР·СғРјС–РҪРҪСҸ РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё: РҝСҖРҫСҖРёРІ РІ РәРҫРјРҝ'СҺСӮРөСҖРҪС–Р№ ліРҪРіРІС–СҒСӮРёСҶС–
РҡС–РҪРөСҶСҢ 1990-С… СӮР° РҝРҫСҮР°СӮРҫРә 2000-С… СҖРҫРәС–РІ РҝСҖРёРҪРөСҒли РІСҒРө РұС–Р»СҢСҲСғ СғвагСғ РҙРҫ РҫРұСҖРҫРұРәРё РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё (NLP) СӮР° РҫРұСҮРёСҒР»СҺвалСҢРҪРҫС— ліРҪРіРІС–СҒСӮРёРәРё. ЗаміСҒСӮСҢ СӮРҫРіРҫ, СүРҫРұ РҪамагаСӮРёСҒСҸ РІСҖСғСҮРҪСғ РәРҫРҙСғРІР°СӮРё РҝСҖавила РҙР»СҸ РәРҫР¶РҪРҫС— РјРҫжливРҫС— взаємРҫРҙС–С—, РҙРҫСҒліРҙРҪРёРәРё РҝРҫСҮали СҖРҫР·СҖРҫРұР»СҸСӮРё СҒСӮР°СӮРёСҒСӮРёСҮРҪС– РјРөСӮРҫРҙРё, СүРҫРұ РҙРҫРҝРҫРјРҫРіСӮРё РәРҫРјРҝ'СҺСӮРөСҖам Р·СҖРҫР·СғРјС–СӮРё РҝСҖРёСӮамаРҪРҪС– Р·Р°РәРҫРҪРҫРјС–СҖРҪРҫСҒСӮС– Р»СҺРҙСҒСҢРәРҫС— РјРҫРІРё.
РҰРөР№ Р·СҒСғРІ СҒСӮав РјРҫжливим завРҙСҸРәРё РәС–Р»СҢРәРҫРј фаРәСӮРҫСҖам: Р·СҖРҫСҒСӮР°СҺСҮС–Р№ РҫРұСҮРёСҒР»СҺвалСҢРҪС–Р№ РҝРҫСӮСғР¶РҪРҫСҒСӮС–, РәСҖР°СүРёРј алгРҫСҖРёСӮмам С–, СүРҫ РҪайважливіСҲРө, РҪР°СҸРІРҪРҫСҒСӮС– РІРөлиРәРёС… СӮРөРәСҒСӮРҫРІРёС… РәРҫСҖРҝСғСҒС–РІ, СҸРәС– РјРҫР¶РҪР° РұСғР»Рҫ Р°РҪалізСғРІР°СӮРё РҙР»СҸ РІРёСҸРІР»РөРҪРҪСҸ ліРҪРіРІС–СҒСӮРёСҮРҪРёС… Р·Р°РәРҫРҪРҫРјС–СҖРҪРҫСҒСӮРөР№. РЎРёСҒСӮРөРјРё РҝРҫСҮали РІРәР»СҺСҮР°СӮРё СӮР°РәС– РјРөСӮРҫРҙРё, СҸРә:
РўРөРіСғРІР°РҪРҪСҸ СҮР°СҒСӮРёРҪ РјРҫРІРё: РІРёР·РҪР°СҮРөРҪРҪСҸ СӮРҫРіРҫ, СҮРё С„СғРҪРәСҶС–РҫРҪСғСҺСӮСҢ СҒР»РҫРІР° СҸРә С–РјРөРҪРҪРёРәРё, РҙС–С”СҒР»РҫРІР°, РҝСҖРёРәРјРөСӮРҪРёРәРё СӮРҫСүРҫ.
Р РҫР·РҝС–Р·РҪаваРҪРҪСҸ С–РјРөРҪРҫРІР°РҪРёС… СҒСғСӮРҪРҫСҒСӮРөР№: РІРёСҸРІР»РөРҪРҪСҸ СӮР° РәлаСҒифіРәР°СҶС–СҸ влаСҒРҪРёС… РҪазв (Р»СҺРҙРөР№, РҫСҖРіР°РҪС–Р·Р°СҶС–Р№, РјС–СҒСҶСҢ).
РҗРҪаліз РҪР°СҒСӮСҖРҫС—РІ: РІРёР·РҪР°СҮРөРҪРҪСҸ РөРјРҫСҶС–Р№РҪРҫРіРҫ СӮРҫРҪСғ СӮРөРәСҒСӮСғ.
РЎРёРҪСӮР°РәСҒРёСҮРҪРёР№ Р°РҪаліз: Р°РҪаліз СҒСӮСҖСғРәСӮСғСҖРё СҖРөСҮРөРҪСҢ РҙР»СҸ РІРёСҸРІР»РөРҪРҪСҸ РіСҖамаСӮРёСҮРҪРёС… Р·РІ'СҸР·РәС–РІ РјС–Р¶ СҒР»Рҫвами.
РһРҙРёРҪ РҝРҫРјС–СӮРҪРёР№ РҝСҖРҫСҖРёРІ РІС–РҙРұСғРІСҒСҸ Р· Watson РІС–Рҙ IBM, СҸРәРёР№ РҝСҖРҫСҒлавивСҒСҸ РҝРөСҖРөРјРҫРіРҫСҺ СҮРөРјРҝС–РҫРҪС–РІ-Р»СҺРҙРөР№ Сғ РІС–РәСӮРҫСҖРёРҪС– Jeopardy! Сғ 2011 СҖРҫСҶС–. РҘРҫСҮР° Watson РҪРө РұСғла СҒСғСӮРҫ СҖРҫР·РјРҫРІРҪРҫСҺ СҒРёСҒСӮРөРјРҫСҺ, РІРҫРҪР° РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖСғвала РұРөР·РҝСҖРөСҶРөРҙРөРҪСӮРҪС– Р·РҙС–РұРҪРҫСҒСӮС– СҖРҫР·СғРјС–СӮРё РҝРёСӮР°РҪРҪСҸ РҝСҖРёСҖРҫРҙРҪРҫСҺ РјРҫРІРҫСҺ, СҲСғРәР°СӮРё Сғ РІРөлиСҮРөР·РҪРёС… СҒС…РҫРІРёСүах Р·РҪР°РҪСҢ СӮР° С„РҫСҖРјСғР»СҺРІР°СӮРё РІС–РҙРҝРҫРІС–РҙС– вҖ“ РјРҫжливРҫСҒСӮС–, СҸРәС– РІРёСҸвилиСҒСҸ РҪРөРҫРұС…С–РҙРҪРёРјРё РҙР»СҸ РҪР°СҒСӮСғРҝРҪРҫРіРҫ РҝРҫРәРҫліРҪРҪСҸ СҮР°СӮ-РұРҫСӮС–РІ. РқРөРІРҙРҫРІР·С– Р·'СҸвилиСҒСҸ РәРҫРјРөСҖСҶС–Р№РҪС– РҝСҖРҫРіСҖами. Siri РІС–Рҙ Apple РұСғла Р·Р°РҝСғСүРөРҪР° Сғ 2011 СҖРҫСҶС–, РҪР°РҙР°СҺСҮРё СҖРҫР·РјРҫРІРҪС– С–РҪСӮРөСҖС„РөР№СҒРё РҝРөСҖРөСҒС–СҮРҪРёРј СҒРҝРҫживаСҮам. РҘРҫСҮР° Siri РұСғла РҫРұРјРөР¶РөРҪР° Р·Р° СҒСғСҮР°СҒРҪРёРјРё СҒСӮР°РҪРҙР°СҖСӮами, РІРҫРҪР° СҸРІР»СҸла СҒРҫРұРҫСҺ Р·РҪР°СҮРҪРёР№ РҝСҖРҫРіСҖРөСҒ Сғ СҒСӮРІРҫСҖРөРҪРҪС– РҝРҫРјС–СҮРҪРёРәС–РІ РЁРҶ РҙР»СҸ РҝРҫРІСҒСҸРәРҙРөРҪРҪРёС… РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ. Р—Р° РҪРөСҺ Р·'СҸвилиСҒСҸ Cortana РІС–Рҙ Microsoft, Assistant РІС–Рҙ Google СӮР° Alexa РІС–Рҙ Amazon, РәРҫР¶РҪР° Р· СҸРәРёС… РҝСҖРҫСҒСғвала РҪайСҒСғСҮР°СҒРҪС–СҲРёР№ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ, РҫСҖС–С”РҪСӮРҫРІР°РҪРёР№ РҪР° СҒРҝРҫживаСҮР°. РқРөзважаСҺСҮРё РҪР° СҶС– РҙРҫСҒСҸРіРҪРөРҪРҪСҸ, СҒРёСҒСӮРөРјРё СӮієї РөРҝРҫС…Рё РІСҒРө СүРө мали СӮСҖСғРҙРҪРҫСүС– Р· РәРҫРҪСӮРөРәСҒСӮРҫРј, Р·РҙРҫСҖРҫРІРёРј РіР»СғР·РҙРҫРј СӮР° РіРөРҪРөСҖСғРІР°РҪРҪСҸРј СҒРҝСҖавРҙС– РҝСҖРёСҖРҫРҙРҪРёС… РІС–РҙРҝРҫРІС–РҙРөР№. Р’РҫРҪРё РұСғли СҒРәлаРҙРҪС–СҲРёРјРё, РҪС–Р¶ С—С…РҪС– РҝРҫРҝРөСҖРөРҙРҪРёРәРё, Р·Р°СҒРҪРҫРІР°РҪС– РҪР° РҝСҖавилах, алРө залиСҲалиСҒСҸ РҝСҖРёРҪСҶРёРҝРҫРІРҫ РҫРұРјРөР¶РөРҪРёРјРё Сғ СҒРІРҫємСғ СҖРҫР·СғРјС–РҪРҪС– РјРҫРІРё СӮР° СҒРІС–СӮСғ.
РҰРөР№ Р·СҒСғРІ СҒСӮав РјРҫжливим завРҙСҸРәРё РәС–Р»СҢРәРҫРј фаРәСӮРҫСҖам: Р·СҖРҫСҒСӮР°СҺСҮС–Р№ РҫРұСҮРёСҒР»СҺвалСҢРҪС–Р№ РҝРҫСӮСғР¶РҪРҫСҒСӮС–, РәСҖР°СүРёРј алгРҫСҖРёСӮмам С–, СүРҫ РҪайважливіСҲРө, РҪР°СҸРІРҪРҫСҒСӮС– РІРөлиРәРёС… СӮРөРәСҒСӮРҫРІРёС… РәРҫСҖРҝСғСҒС–РІ, СҸРәС– РјРҫР¶РҪР° РұСғР»Рҫ Р°РҪалізСғРІР°СӮРё РҙР»СҸ РІРёСҸРІР»РөРҪРҪСҸ ліРҪРіРІС–СҒСӮРёСҮРҪРёС… Р·Р°РәРҫРҪРҫРјС–СҖРҪРҫСҒСӮРөР№. РЎРёСҒСӮРөРјРё РҝРҫСҮали РІРәР»СҺСҮР°СӮРё СӮР°РәС– РјРөСӮРҫРҙРё, СҸРә:
РўРөРіСғРІР°РҪРҪСҸ СҮР°СҒСӮРёРҪ РјРҫРІРё: РІРёР·РҪР°СҮРөРҪРҪСҸ СӮРҫРіРҫ, СҮРё С„СғРҪРәСҶС–РҫРҪСғСҺСӮСҢ СҒР»РҫРІР° СҸРә С–РјРөРҪРҪРёРәРё, РҙС–С”СҒР»РҫРІР°, РҝСҖРёРәРјРөСӮРҪРёРәРё СӮРҫСүРҫ.
Р РҫР·РҝС–Р·РҪаваРҪРҪСҸ С–РјРөРҪРҫРІР°РҪРёС… СҒСғСӮРҪРҫСҒСӮРөР№: РІРёСҸРІР»РөРҪРҪСҸ СӮР° РәлаСҒифіРәР°СҶС–СҸ влаСҒРҪРёС… РҪазв (Р»СҺРҙРөР№, РҫСҖРіР°РҪС–Р·Р°СҶС–Р№, РјС–СҒСҶСҢ).
РҗРҪаліз РҪР°СҒСӮСҖРҫС—РІ: РІРёР·РҪР°СҮРөРҪРҪСҸ РөРјРҫСҶС–Р№РҪРҫРіРҫ СӮРҫРҪСғ СӮРөРәСҒСӮСғ.
РЎРёРҪСӮР°РәСҒРёСҮРҪРёР№ Р°РҪаліз: Р°РҪаліз СҒСӮСҖСғРәСӮСғСҖРё СҖРөСҮРөРҪСҢ РҙР»СҸ РІРёСҸРІР»РөРҪРҪСҸ РіСҖамаСӮРёСҮРҪРёС… Р·РІ'СҸР·РәС–РІ РјС–Р¶ СҒР»Рҫвами.
РһРҙРёРҪ РҝРҫРјС–СӮРҪРёР№ РҝСҖРҫСҖРёРІ РІС–РҙРұСғРІСҒСҸ Р· Watson РІС–Рҙ IBM, СҸРәРёР№ РҝСҖРҫСҒлавивСҒСҸ РҝРөСҖРөРјРҫРіРҫСҺ СҮРөРјРҝС–РҫРҪС–РІ-Р»СҺРҙРөР№ Сғ РІС–РәСӮРҫСҖРёРҪС– Jeopardy! Сғ 2011 СҖРҫСҶС–. РҘРҫСҮР° Watson РҪРө РұСғла СҒСғСӮРҫ СҖРҫР·РјРҫРІРҪРҫСҺ СҒРёСҒСӮРөРјРҫСҺ, РІРҫРҪР° РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖСғвала РұРөР·РҝСҖРөСҶРөРҙРөРҪСӮРҪС– Р·РҙС–РұРҪРҫСҒСӮС– СҖРҫР·СғРјС–СӮРё РҝРёСӮР°РҪРҪСҸ РҝСҖРёСҖРҫРҙРҪРҫСҺ РјРҫРІРҫСҺ, СҲСғРәР°СӮРё Сғ РІРөлиСҮРөР·РҪРёС… СҒС…РҫРІРёСүах Р·РҪР°РҪСҢ СӮР° С„РҫСҖРјСғР»СҺРІР°СӮРё РІС–РҙРҝРҫРІС–РҙС– вҖ“ РјРҫжливРҫСҒСӮС–, СҸРәС– РІРёСҸвилиСҒСҸ РҪРөРҫРұС…С–РҙРҪРёРјРё РҙР»СҸ РҪР°СҒСӮСғРҝРҪРҫРіРҫ РҝРҫРәРҫліРҪРҪСҸ СҮР°СӮ-РұРҫСӮС–РІ. РқРөРІРҙРҫРІР·С– Р·'СҸвилиСҒСҸ РәРҫРјРөСҖСҶС–Р№РҪС– РҝСҖРҫРіСҖами. Siri РІС–Рҙ Apple РұСғла Р·Р°РҝСғСүРөРҪР° Сғ 2011 СҖРҫСҶС–, РҪР°РҙР°СҺСҮРё СҖРҫР·РјРҫРІРҪС– С–РҪСӮРөСҖС„РөР№СҒРё РҝРөСҖРөСҒС–СҮРҪРёРј СҒРҝРҫживаСҮам. РҘРҫСҮР° Siri РұСғла РҫРұРјРөР¶РөРҪР° Р·Р° СҒСғСҮР°СҒРҪРёРјРё СҒСӮР°РҪРҙР°СҖСӮами, РІРҫРҪР° СҸРІР»СҸла СҒРҫРұРҫСҺ Р·РҪР°СҮРҪРёР№ РҝСҖРҫРіСҖРөСҒ Сғ СҒСӮРІРҫСҖРөРҪРҪС– РҝРҫРјС–СҮРҪРёРәС–РІ РЁРҶ РҙР»СҸ РҝРҫРІСҒСҸРәРҙРөРҪРҪРёС… РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ. Р—Р° РҪРөСҺ Р·'СҸвилиСҒСҸ Cortana РІС–Рҙ Microsoft, Assistant РІС–Рҙ Google СӮР° Alexa РІС–Рҙ Amazon, РәРҫР¶РҪР° Р· СҸРәРёС… РҝСҖРҫСҒСғвала РҪайСҒСғСҮР°СҒРҪС–СҲРёР№ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ, РҫСҖС–С”РҪСӮРҫРІР°РҪРёР№ РҪР° СҒРҝРҫживаСҮР°. РқРөзважаСҺСҮРё РҪР° СҶС– РҙРҫСҒСҸРіРҪРөРҪРҪСҸ, СҒРёСҒСӮРөРјРё СӮієї РөРҝРҫС…Рё РІСҒРө СүРө мали СӮСҖСғРҙРҪРҫСүС– Р· РәРҫРҪСӮРөРәСҒСӮРҫРј, Р·РҙРҫСҖРҫРІРёРј РіР»СғР·РҙРҫРј СӮР° РіРөРҪРөСҖСғРІР°РҪРҪСҸРј СҒРҝСҖавРҙС– РҝСҖРёСҖРҫРҙРҪРёС… РІС–РҙРҝРҫРІС–РҙРөР№. Р’РҫРҪРё РұСғли СҒРәлаРҙРҪС–СҲРёРјРё, РҪС–Р¶ С—С…РҪС– РҝРҫРҝРөСҖРөРҙРҪРёРәРё, Р·Р°СҒРҪРҫРІР°РҪС– РҪР° РҝСҖавилах, алРө залиСҲалиСҒСҸ РҝСҖРёРҪСҶРёРҝРҫРІРҫ РҫРұРјРөР¶РөРҪРёРјРё Сғ СҒРІРҫємСғ СҖРҫР·СғРјС–РҪРҪС– РјРҫРІРё СӮР° СҒРІС–СӮСғ.
РңР°СҲРёРҪРҪРө РҪавСҮР°РҪРҪСҸ СӮР° РҝС–РҙС…С–Рҙ, РәРөСҖРҫРІР°РҪРёР№ РҙР°РҪРёРјРё
РЎРөСҖРөРҙРёРҪР° 2010-С… СҖРҫРәС–РІ РҫР·РҪамРөРҪСғвала СҮРөСҖРіРҫРІСғ Р·РјС–РҪСғ РҝР°СҖР°РҙРёРіРјРё РІ СҖРҫР·РјРҫРІРҪРҫРјСғ СҲСӮСғСҮРҪРҫРјСғ С–РҪСӮРөР»РөРәСӮС– Р· РјР°СҒРҫРІРёРј РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸРј РјРөСӮРҫРҙС–РІ РјР°СҲРёРҪРҪРҫРіРҫ РҪавСҮР°РҪРҪСҸ. ЗаміСҒСӮСҢ СӮРҫРіРҫ, СүРҫРұ РҝРҫРәлаРҙР°СӮРёСҒСҸ РҪР° РІСҖСғСҮРҪСғ СҒСӮРІРҫСҖРөРҪС– РҝСҖавила СҮРё РҫРұРјРөР¶РөРҪС– СҒСӮР°СӮРёСҒСӮРёСҮРҪС– РјРҫРҙРөлі, С–РҪР¶РөРҪРөСҖРё РҝРҫСҮали СҒСӮРІРҫСҖСҺРІР°СӮРё СҒРёСҒСӮРөРјРё, СҸРәС– РјРҫгли РІРёРІСҮР°СӮРё Р·Р°РәРҫРҪРҫРјС–СҖРҪРҫСҒСӮС– РұРөР·РҝРҫСҒРөСҖРөРҙРҪСҢРҫ Р· РҙР°РҪРёС… вҖ“ С– Р· РІРөлиРәРҫС— С—С… РәС–Р»СҢРәРҫСҒСӮС–.
РҰСҸ РөРҝРҫС…Р° РҫР·РҪамРөРҪСғвала Р·СҖРҫСҒСӮР°РҪРҪСҸ РәлаСҒифіРәР°СҶС–С— РҪаміСҖС–РІ СӮР° РІРёР»СғСҮРөРҪРҪСҸ СҒСғСӮРҪРҫСҒСӮРөР№ СҸРә РҫСҒРҪРҫРІРҪРёС… РәРҫРјРҝРҫРҪРөРҪСӮС–РІ СҖРҫР·РјРҫРІРҪРҫС— Р°СҖС…С–СӮРөРәСӮСғСҖРё. РҡРҫли РәРҫСҖРёСҒСӮСғРІР°СҮ СҖРҫРұРёРІ Р·Р°РҝРёСӮ, СҒРёСҒСӮРөРјР°:
РҡлаСҒифіРәСғвала загалСҢРҪРёР№ РҪаміСҖ (РҪР°РҝСҖРёРәлаРҙ, РұСҖРҫРҪСҺРІР°РҪРҪСҸ авіаРәРІРёСӮРәР°, РҝРөСҖРөРІС–СҖРәР° РҝРҫРіРҫРҙРё, РІС–РҙСӮРІРҫСҖРөРҪРҪСҸ РјСғР·РёРәРё)
Р’РёР»СғСҮала РІС–РҙРҝРҫРІС–РҙРҪС– СҒСғСӮРҪРҫСҒСӮС– (РҪР°РҝСҖРёРәлаРҙ, РјС–СҒСҶСҸ СҖРҫР·СӮР°СҲСғРІР°РҪРҪСҸ, РҙР°СӮРё, РҪазви РҝС–СҒРөРҪСҢ)
Р—С–СҒСӮавлСҸла С—С… Р· РҝРөРІРҪРёРјРё РҙС–СҸРјРё Р°РұРҫ РІС–РҙРҝРҫРІС–РҙСҸРјРё
Р—Р°РҝСғСҒРә Facebook (СӮРөРҝРөСҖ Meta) СҒРІРҫєї РҝлаСӮС„РҫСҖРјРё Messenger Сғ 2016 СҖРҫСҶС– РҙРҫР·РІРҫлив СҖРҫР·СҖРҫРұРҪРёРәам СҒСӮРІРҫСҖСҺРІР°СӮРё СҮР°СӮ-РұРҫСӮС–РІ, СҸРәС– РјРҫгли РҫС…РҫРҝРёСӮРё РјС–Р»СҢР№РҫРҪРё РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ, СүРҫ РІРёРәлиРәалРҫ С…РІРёР»СҺ РәРҫРјРөСҖСҶС–Р№РҪРҫРіРҫ С–РҪСӮРөСҖРөСҒСғ. БагаСӮРҫ РәРҫРјРҝР°РҪС–Р№ РҝРҫСҒРҝС–СҲили РІРҝСҖРҫРІР°РҙР¶СғРІР°СӮРё СҮР°СӮ-РұРҫСӮС–РІ, С…РҫСҮР° СҖРөР·СғР»СҢСӮР°СӮРё РұСғли РҪРөРҫРҙРҪРҫР·РҪР°СҮРҪРёРјРё. Р Р°РҪРҪС– РәРҫРјРөСҖСҶС–Р№РҪС– РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҮР°СҒСӮРҫ РҙСҖР°СӮСғвали РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ РҫРұРјРөР¶РөРҪРёРј СҖРҫР·СғРјС–РҪРҪСҸРј СӮР° Р¶РҫСҖСҒСӮРәРёРјРё РҝСҖРҫСҶРөСҒами СҖРҫР·РјРҫРІРё.
РўРөС…РҪС–СҮРҪР° Р°СҖС…С–СӮРөРәСӮСғСҖР° СҖРҫР·РјРҫРІРҪРёС… СҒРёСҒСӮРөРј СӮР°РәРҫР¶ СҖРҫзвивалаСҒСҸ РҝСҖРҫСӮСҸРіРҫРј СҶСҢРҫРіРҫ РҝРөСҖС–РҫРҙСғ. РўРёРҝРҫРІРёР№ РҝС–РҙС…С–Рҙ РҝРөСҖРөРҙРұР°СҮав РәРҫРҪРІРөС”СҖ СҒРҝРөСҶіалізРҫРІР°РҪРёС… РәРҫРјРҝРҫРҪРөРҪСӮС–РІ:
РҗРІСӮРҫРјР°СӮРёСҮРҪРө СҖРҫР·РҝС–Р·РҪаваРҪРҪСҸ РјРҫРІР»РөРҪРҪСҸ (РҙР»СҸ РіРҫР»РҫСҒРҫРІРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ)
Р РҫР·СғРјС–РҪРҪСҸ РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё
РҡРөСҖСғРІР°РҪРҪСҸ РҙіалРҫгами
Р“РөРҪРөСҖР°СҶС–СҸ РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё
РҹРөСҖРөСӮРІРҫСҖРөРҪРҪСҸ СӮРөРәСҒСӮСғ РІ РјРҫРІР»РөРҪРҪСҸ (РҙР»СҸ РіРҫР»РҫСҒРҫРІРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ)
РҡРҫР¶РөРҪ РәРҫРјРҝРҫРҪРөРҪСӮ РјРҫР¶РҪР° РұСғР»Рҫ РҫРҝСӮРёРјС–Р·СғРІР°СӮРё РҫРәСҖРөРјРҫ, СүРҫ РҙРҫР·РІРҫР»СҸР»Рҫ РҝРҫСҒСӮСғРҝРҫРІС– РҝРҫРәСҖР°СүРөРҪРҪСҸ. РһРҙРҪР°Рә СҶС– РәРҫРҪРІРөС”СҖРҪС– Р°СҖС…С–СӮРөРәСӮСғСҖРё С–РҪРҫРҙС– СҒСӮСҖажРҙали РІС–Рҙ РҝРҫСҲРёСҖРөРҪРҪСҸ РҝРҫРјРёР»РҫРә вҖ“ РҝРҫРјРёР»РәРё РҪР° СҖР°РҪРҪС–С… СҒСӮР°РҙС–СҸС… РәР°СҒРәР°РҙРҪРҫ РҝРҫСҲРёСҖСҺвалиСҒСҸ РҝРҫ РІСҒС–Р№ СҒРёСҒСӮРөРјС–.
РҘРҫСҮР° РјР°СҲРёРҪРҪРө РҪавСҮР°РҪРҪСҸ Р·РҪР°СҮРҪРҫ РҝРҫРәСҖР°СүРёР»Рҫ РјРҫжливРҫСҒСӮС–, СҒРёСҒСӮРөРјРё РІСҒРө СүРө мали СӮСҖСғРҙРҪРҫСүС– Р·С– Р·РұРөСҖРөР¶РөРҪРҪСҸРј РәРҫРҪСӮРөРәСҒСӮСғ РҝС–Рҙ СҮР°СҒ СӮСҖивалих СҖРҫР·РјРҫРІ, СҖРҫР·СғРјС–РҪРҪСҸРј РҪРөСҸРІРҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С— СӮР° РіРөРҪРөСҖСғРІР°РҪРҪСҸРј СҒРҝСҖавРҙС– СҖС–Р·РҪРҫРјР°РҪС–СӮРҪРёС… С– РҝСҖРёСҖРҫРҙРҪРёС… РІС–РҙРҝРҫРІС–РҙРөР№. РқР°СҒСӮСғРҝРҪРёР№ РҝСҖРҫСҖРёРІ вимагав РұРё РұС–Р»СҢСҲ СҖР°РҙРёРәалСҢРҪРҫРіРҫ РҝС–РҙС…РҫРҙСғ.
РҰСҸ РөРҝРҫС…Р° РҫР·РҪамРөРҪСғвала Р·СҖРҫСҒСӮР°РҪРҪСҸ РәлаСҒифіРәР°СҶС–С— РҪаміСҖС–РІ СӮР° РІРёР»СғСҮРөРҪРҪСҸ СҒСғСӮРҪРҫСҒСӮРөР№ СҸРә РҫСҒРҪРҫРІРҪРёС… РәРҫРјРҝРҫРҪРөРҪСӮС–РІ СҖРҫР·РјРҫРІРҪРҫС— Р°СҖС…С–СӮРөРәСӮСғСҖРё. РҡРҫли РәРҫСҖРёСҒСӮСғРІР°СҮ СҖРҫРұРёРІ Р·Р°РҝРёСӮ, СҒРёСҒСӮРөРјР°:
РҡлаСҒифіРәСғвала загалСҢРҪРёР№ РҪаміСҖ (РҪР°РҝСҖРёРәлаРҙ, РұСҖРҫРҪСҺРІР°РҪРҪСҸ авіаРәРІРёСӮРәР°, РҝРөСҖРөРІС–СҖРәР° РҝРҫРіРҫРҙРё, РІС–РҙСӮРІРҫСҖРөРҪРҪСҸ РјСғР·РёРәРё)
Р’РёР»СғСҮала РІС–РҙРҝРҫРІС–РҙРҪС– СҒСғСӮРҪРҫСҒСӮС– (РҪР°РҝСҖРёРәлаРҙ, РјС–СҒСҶСҸ СҖРҫР·СӮР°СҲСғРІР°РҪРҪСҸ, РҙР°СӮРё, РҪазви РҝС–СҒРөРҪСҢ)
Р—С–СҒСӮавлСҸла С—С… Р· РҝРөРІРҪРёРјРё РҙС–СҸРјРё Р°РұРҫ РІС–РҙРҝРҫРІС–РҙСҸРјРё
Р—Р°РҝСғСҒРә Facebook (СӮРөРҝРөСҖ Meta) СҒРІРҫєї РҝлаСӮС„РҫСҖРјРё Messenger Сғ 2016 СҖРҫСҶС– РҙРҫР·РІРҫлив СҖРҫР·СҖРҫРұРҪРёРәам СҒСӮРІРҫСҖСҺРІР°СӮРё СҮР°СӮ-РұРҫСӮС–РІ, СҸРәС– РјРҫгли РҫС…РҫРҝРёСӮРё РјС–Р»СҢР№РҫРҪРё РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ, СүРҫ РІРёРәлиРәалРҫ С…РІРёР»СҺ РәРҫРјРөСҖСҶС–Р№РҪРҫРіРҫ С–РҪСӮРөСҖРөСҒСғ. БагаСӮРҫ РәРҫРјРҝР°РҪС–Р№ РҝРҫСҒРҝС–СҲили РІРҝСҖРҫРІР°РҙР¶СғРІР°СӮРё СҮР°СӮ-РұРҫСӮС–РІ, С…РҫСҮР° СҖРөР·СғР»СҢСӮР°СӮРё РұСғли РҪРөРҫРҙРҪРҫР·РҪР°СҮРҪРёРјРё. Р Р°РҪРҪС– РәРҫРјРөСҖСҶС–Р№РҪС– РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҮР°СҒСӮРҫ РҙСҖР°СӮСғвали РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ РҫРұРјРөР¶РөРҪРёРј СҖРҫР·СғРјС–РҪРҪСҸРј СӮР° Р¶РҫСҖСҒСӮРәРёРјРё РҝСҖРҫСҶРөСҒами СҖРҫР·РјРҫРІРё.
РўРөС…РҪС–СҮРҪР° Р°СҖС…С–СӮРөРәСӮСғСҖР° СҖРҫР·РјРҫРІРҪРёС… СҒРёСҒСӮРөРј СӮР°РәРҫР¶ СҖРҫзвивалаСҒСҸ РҝСҖРҫСӮСҸРіРҫРј СҶСҢРҫРіРҫ РҝРөСҖС–РҫРҙСғ. РўРёРҝРҫРІРёР№ РҝС–РҙС…С–Рҙ РҝРөСҖРөРҙРұР°СҮав РәРҫРҪРІРөС”СҖ СҒРҝРөСҶіалізРҫРІР°РҪРёС… РәРҫРјРҝРҫРҪРөРҪСӮС–РІ:
РҗРІСӮРҫРјР°СӮРёСҮРҪРө СҖРҫР·РҝС–Р·РҪаваРҪРҪСҸ РјРҫРІР»РөРҪРҪСҸ (РҙР»СҸ РіРҫР»РҫСҒРҫРІРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ)
Р РҫР·СғРјС–РҪРҪСҸ РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё
РҡРөСҖСғРІР°РҪРҪСҸ РҙіалРҫгами
Р“РөРҪРөСҖР°СҶС–СҸ РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё
РҹРөСҖРөСӮРІРҫСҖРөРҪРҪСҸ СӮРөРәСҒСӮСғ РІ РјРҫРІР»РөРҪРҪСҸ (РҙР»СҸ РіРҫР»РҫСҒРҫРІРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ)
РҡРҫР¶РөРҪ РәРҫРјРҝРҫРҪРөРҪСӮ РјРҫР¶РҪР° РұСғР»Рҫ РҫРҝСӮРёРјС–Р·СғРІР°СӮРё РҫРәСҖРөРјРҫ, СүРҫ РҙРҫР·РІРҫР»СҸР»Рҫ РҝРҫСҒСӮСғРҝРҫРІС– РҝРҫРәСҖР°СүРөРҪРҪСҸ. РһРҙРҪР°Рә СҶС– РәРҫРҪРІРөС”СҖРҪС– Р°СҖС…С–СӮРөРәСӮСғСҖРё С–РҪРҫРҙС– СҒСӮСҖажРҙали РІС–Рҙ РҝРҫСҲРёСҖРөРҪРҪСҸ РҝРҫРјРёР»РҫРә вҖ“ РҝРҫРјРёР»РәРё РҪР° СҖР°РҪРҪС–С… СҒСӮР°РҙС–СҸС… РәР°СҒРәР°РҙРҪРҫ РҝРҫСҲРёСҖСҺвалиСҒСҸ РҝРҫ РІСҒС–Р№ СҒРёСҒСӮРөРјС–.
РҘРҫСҮР° РјР°СҲРёРҪРҪРө РҪавСҮР°РҪРҪСҸ Р·РҪР°СҮРҪРҫ РҝРҫРәСҖР°СүРёР»Рҫ РјРҫжливРҫСҒСӮС–, СҒРёСҒСӮРөРјРё РІСҒРө СүРө мали СӮСҖСғРҙРҪРҫСүС– Р·С– Р·РұРөСҖРөР¶РөРҪРҪСҸРј РәРҫРҪСӮРөРәСҒСӮСғ РҝС–Рҙ СҮР°СҒ СӮСҖивалих СҖРҫР·РјРҫРІ, СҖРҫР·СғРјС–РҪРҪСҸРј РҪРөСҸРІРҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С— СӮР° РіРөРҪРөСҖСғРІР°РҪРҪСҸРј СҒРҝСҖавРҙС– СҖС–Р·РҪРҫРјР°РҪС–СӮРҪРёС… С– РҝСҖРёСҖРҫРҙРҪРёС… РІС–РҙРҝРҫРІС–РҙРөР№. РқР°СҒСӮСғРҝРҪРёР№ РҝСҖРҫСҖРёРІ вимагав РұРё РұС–Р»СҢСҲ СҖР°РҙРёРәалСҢРҪРҫРіРҫ РҝС–РҙС…РҫРҙСғ.
Р РөРІРҫР»СҺСҶС–СҸ СӮСҖР°РҪСҒС„РҫСҖРјР°СӮРҫСҖС–РІ: РјРҫРҙРөлі РҪРөР№СҖРҫРҪРҪРҫС— РјРҫРІРё
2017 СҖС–Рә СҒСӮав РҝРөСҖРөР»РҫРјРҪРёРј РІ С–СҒСӮРҫСҖС–С— СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ Р· РҝСғРұліРәР°СҶС–С”СҺ РәРҪРёРіРё «Увага вҖ” СҶРө РІСҒРө, СүРҫ вам РҝРҫСӮСҖС–РұРҪРҫВ», РІ СҸРәС–Р№ РұСғР»Рҫ РҝСҖРөРҙСҒСӮавлРөРҪРҫ Р°СҖС…С–СӮРөРәСӮСғСҖСғ Transformer, СҸРәР° мала СҖРөРІРҫР»СҺСҶС–РҫРҪС–Р·СғРІР°СӮРё РҫРұСҖРҫРұРәСғ РҝСҖРёСҖРҫРҙРҪРҫС— РјРҫРІРё. РқР° РІС–РҙРјС–РҪСғ РІС–Рҙ РҝРҫРҝРөСҖРөРҙРҪС–С… РҝС–РҙС…РҫРҙС–РІ, СҸРәС– РҝРҫСҒліРҙРҫРІРҪРҫ РҫРұСҖРҫРұР»СҸли СӮРөРәСҒСӮ, Transformers РјРҫгли СҖРҫР·РіР»СҸРҙР°СӮРё РІРөСҒСҢ СғСҖРёРІРҫРә РҫРҙРҪРҫСҮР°СҒРҪРҫ, СүРҫ РҙРҫР·РІРҫР»СҸР»Рҫ С—Рј РәСҖР°СүРө фіРәСҒСғРІР°СӮРё Р·РІ'СҸР·РәРё РјС–Р¶ СҒР»Рҫвами РҪРөзалРөР¶РҪРҫ РІС–Рҙ С—С…РҪСҢРҫС— РІС–РҙСҒСӮР°РҪС– РҫРҙРҪРө РІС–Рҙ РҫРҙРҪРҫРіРҫ.
РҰРө РҪРҫРІРҫРІРІРөРҙРөРҪРҪСҸ РҙРҫР·РІРҫлилРҫ СҖРҫР·СҖРҫРұРёСӮРё РҙРөРҙалі РҝРҫСӮСғР¶РҪС–СҲС– РјРҫРІРҪС– РјРҫРҙРөлі. РЈ 2018 СҖРҫСҶС– Google РҝСҖРөРҙСҒСӮавила BERT (Bidirectional Encoder Representations from Transformers), СүРҫ Р·РҪР°СҮРҪРҫ РҝРҫРәСҖР°СүРёР»Рҫ РҝСҖРҫРҙСғРәСӮРёРІРҪС–СҒСӮСҢ Сғ СҖС–Р·РҪРёС… завРҙР°РҪРҪСҸС… СҖРҫР·СғРјС–РҪРҪСҸ РјРҫРІРё. РЈ 2019 СҖРҫСҶС– OpenAI РІРёРҝСғСҒСӮила GPT-2, РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖСғвавСҲРё РұРөР·РҝСҖРөСҶРөРҙРөРҪСӮРҪС– РјРҫжливРҫСҒСӮС– Сғ СҒСӮРІРҫСҖРөРҪРҪС– Р·РІ'СҸР·РҪРҫРіРҫ, РәРҫРҪСӮРөРәСҒСӮСғалСҢРҪРҫ СҖРөР»РөРІР°РҪСӮРҪРҫРіРҫ СӮРөРәСҒСӮСғ.
РқайРұС–Р»СҢСҲ РІСҖажаСҺСҮРёР№ СҒСӮСҖРёРұРҫРә РІС–РҙРұСғРІСҒСҸ Сғ 2020 СҖРҫСҶС– Р· GPT-3, РјР°СҒСҲСӮР°РұСғРІР°РҪРҪСҸ СҸРәРҫРіРҫ РҙРҫСҒСҸРіР»Рҫ 175 РјС–Р»СҢСҸСҖРҙС–РІ РҝР°СҖамРөСӮСҖС–РІ (РҝРҫСҖС–РІРҪСҸРҪРҫ Р· 1,5 РјС–Р»СҢСҸСҖРҙами Сғ GPT-2). РҰРө Р·РҪР°СҮРҪРө Р·РұС–Р»СҢСҲРөРҪРҪСҸ РјР°СҒСҲСӮР°РұСғ РІ РҝРҫС”РҙРҪР°РҪРҪС– Р· Р°СҖС…С–СӮРөРәСӮСғСҖРҪРёРјРё РІРҙРҫСҒРәРҫРҪалРөРҪРҪСҸРјРё СҒСӮРІРҫСҖРёР»Рҫ СҸРәС–СҒРҪРҫ С–РҪСҲС– РјРҫжливРҫСҒСӮС–. GPT-3 РјС–Рі РіРөРҪРөСҖСғРІР°СӮРё СӮРөРәСҒСӮ, РҪР°РҙР·РІРёСҮайРҪРҫ СҒС…Рҫжий РҪР° Р»СҺРҙСҒСҢРәРёР№, СҖРҫР·СғРјС–СӮРё РәРҫРҪСӮРөРәСҒСӮ СӮРёСҒСҸСҮ СҒлів С– РҪавіСӮСҢ РІРёРәРҫРҪСғРІР°СӮРё завРҙР°РҪРҪСҸ, РҪР° СҸРәРёС… РІС–РҪ РҪРө РұСғРІ СҒРҝРөСҶіалСҢРҪРҫ РҪавСҮРөРҪРёР№.
ДлСҸ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ СҶС– РҙРҫСҒСҸРіРҪРөРҪРҪСҸ РҝРөСҖРөСӮРІРҫСҖилиСҒСҸ РҪР° СҮР°СӮ-РұРҫСӮС–РІ, СҸРәС– РјРҫгли:
РҹС–РҙСӮСҖРёРјСғРІР°СӮРё Р·РІ'СҸР·РҪС– СҖРҫР·РјРҫРІРё РҝСҖРҫСӮСҸРіРҫРј РұагаСӮСҢРҫС… РөСӮР°РҝС–РІ
Р РҫР·СғРјС–СӮРё РҪСҺР°РҪСҒРҫРІР°РҪС– Р·Р°РҝРёСӮРё РұРөР· СҒРҝРөСҶіалСҢРҪРҫРіРҫ РҪавСҮР°РҪРҪСҸ
Р“РөРҪРөСҖСғРІР°СӮРё СҖС–Р·РҪРҫРјР°РҪС–СӮРҪС–, РәРҫРҪСӮРөРәСҒСӮСғалСҢРҪРҫ РІС–РҙРҝРҫРІС–РҙРҪС– РІС–РҙРҝРҫРІС–РҙС–
РҗРҙР°РҝСӮСғРІР°СӮРё СҒРІС–Р№ СӮРҫРҪ С– СҒСӮРёР»СҢ РІС–РҙРҝРҫРІС–РҙРҪРҫ РҙРҫ РәРҫСҖРёСҒСӮСғРІР°СҮР°
РһРұСҖРҫРұР»СҸСӮРё РҪРөРҫРҙРҪРҫР·РҪР°СҮРҪС–СҒСӮСҢ СӮР° СғСӮРҫСҮРҪСҺРІР°СӮРё Р·Р° РҪРөРҫРұС…С–РҙРҪРҫСҒСӮС–
Р’РёРҝСғСҒРә ChatGPT РҪР°РҝСҖРёРәС–РҪСҶС– 2022 СҖРҫРәСғ Р·СҖРҫРұРёРІ СҶС– РјРҫжливРҫСҒСӮС– РҝРҫСҲРёСҖРөРҪРёРјРё, залСғСҮРёРІСҲРё РҝРҫРҪР°Рҙ РјС–Р»СҢР№РҫРҪ РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ РҝСҖРҫСӮСҸРіРҫРј РәС–Р»СҢРәРҫС… РҙРҪС–РІ РҝС–СҒР»СҸ Р·Р°РҝСғСҒРәСғ. Р Р°РҝСӮРҫРј СҲРёСҖРҫРәР° РіСҖРҫРјР°РҙСҒСҢРәС–СҒСӮСҢ РҫСӮСҖимала РҙРҫСҒСӮСғРҝ РҙРҫ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ, СҸРәРёР№ Р·РҙававСҒСҸ СҸРәС–СҒРҪРҫ РІС–РҙРјС–РҪРҪРёРј РІС–Рҙ СғСҒСҢРҫРіРҫ, СүРҫ РұСғР»Рҫ СҖР°РҪС–СҲРө вҖ“ РұС–Р»СҢСҲ РіРҪСғСҮРәРёРј, РұС–Р»СҢСҲ РҫРұС–Р·РҪР°РҪРёРј СӮР° РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРёРј Сғ СҒРІРҫС—Р№ взаємРҫРҙС–С—.
РҡРҫРјРөСҖСҶС–Р№РҪС– РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҲРІРёРҙРәРҫ РІС–РҙРұСғлиСҒСҸ, С– РәРҫРјРҝР°РҪС–С— РҝРҫСҮали РІРҝСҖРҫРІР°РҙР¶СғРІР°СӮРё РІРөлиРәС– РјРҫРІРҪС– РјРҫРҙРөлі Сғ СҒРІРҫС— РҝлаСӮС„РҫСҖРјРё РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ, С–РҪСҒСӮСҖСғРјРөРҪСӮРё РҙР»СҸ СҒСӮРІРҫСҖРөРҪРҪСҸ РәРҫРҪСӮРөРҪСӮСғ СӮР° РҝСҖРҫРіСҖами РҙР»СҸ РҝС–РҙРІРёСүРөРҪРҪСҸ РҝСҖРҫРҙСғРәСӮРёРІРҪРҫСҒСӮС–. РЁРІРёРҙРәРө РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ РІС–РҙРҫРұСҖажалРҫ СҸРә СӮРөС…РҪРҫР»РҫРіС–СҮРҪРёР№ СҒСӮСҖРёРұРҫРә, СӮР°Рә С– С–РҪСӮСғС—СӮРёРІРҪРҫ Р·СҖРҫР·Сғмілий С–РҪСӮРөСҖС„РөР№СҒ, СҸРәРёР№ РҪР°Рҙавали СҶС– РјРҫРҙРөлі вҖ“ Р·СҖРөСҲСӮРҫСҺ, СҖРҫР·РјРҫРІР° вҖ“ СҶРө РҪайРҝСҖРёСҖРҫРҙРҪС–СҲРёР№ СҒРҝРҫСҒС–Рұ СҒРҝС–Р»РәСғРІР°РҪРҪСҸ Р»СҺРҙРөР№.
РҰРө РҪРҫРІРҫРІРІРөРҙРөРҪРҪСҸ РҙРҫР·РІРҫлилРҫ СҖРҫР·СҖРҫРұРёСӮРё РҙРөРҙалі РҝРҫСӮСғР¶РҪС–СҲС– РјРҫРІРҪС– РјРҫРҙРөлі. РЈ 2018 СҖРҫСҶС– Google РҝСҖРөРҙСҒСӮавила BERT (Bidirectional Encoder Representations from Transformers), СүРҫ Р·РҪР°СҮРҪРҫ РҝРҫРәСҖР°СүРёР»Рҫ РҝСҖРҫРҙСғРәСӮРёРІРҪС–СҒСӮСҢ Сғ СҖС–Р·РҪРёС… завРҙР°РҪРҪСҸС… СҖРҫР·СғРјС–РҪРҪСҸ РјРҫРІРё. РЈ 2019 СҖРҫСҶС– OpenAI РІРёРҝСғСҒСӮила GPT-2, РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖСғвавСҲРё РұРөР·РҝСҖРөСҶРөРҙРөРҪСӮРҪС– РјРҫжливРҫСҒСӮС– Сғ СҒСӮРІРҫСҖРөРҪРҪС– Р·РІ'СҸР·РҪРҫРіРҫ, РәРҫРҪСӮРөРәСҒСӮСғалСҢРҪРҫ СҖРөР»РөРІР°РҪСӮРҪРҫРіРҫ СӮРөРәСҒСӮСғ.
РқайРұС–Р»СҢСҲ РІСҖажаСҺСҮРёР№ СҒСӮСҖРёРұРҫРә РІС–РҙРұСғРІСҒСҸ Сғ 2020 СҖРҫСҶС– Р· GPT-3, РјР°СҒСҲСӮР°РұСғРІР°РҪРҪСҸ СҸРәРҫРіРҫ РҙРҫСҒСҸРіР»Рҫ 175 РјС–Р»СҢСҸСҖРҙС–РІ РҝР°СҖамРөСӮСҖС–РІ (РҝРҫСҖС–РІРҪСҸРҪРҫ Р· 1,5 РјС–Р»СҢСҸСҖРҙами Сғ GPT-2). РҰРө Р·РҪР°СҮРҪРө Р·РұС–Р»СҢСҲРөРҪРҪСҸ РјР°СҒСҲСӮР°РұСғ РІ РҝРҫС”РҙРҪР°РҪРҪС– Р· Р°СҖС…С–СӮРөРәСӮСғСҖРҪРёРјРё РІРҙРҫСҒРәРҫРҪалРөРҪРҪСҸРјРё СҒСӮРІРҫСҖРёР»Рҫ СҸРәС–СҒРҪРҫ С–РҪСҲС– РјРҫжливРҫСҒСӮС–. GPT-3 РјС–Рі РіРөРҪРөСҖСғРІР°СӮРё СӮРөРәСҒСӮ, РҪР°РҙР·РІРёСҮайРҪРҫ СҒС…Рҫжий РҪР° Р»СҺРҙСҒСҢРәРёР№, СҖРҫР·СғРјС–СӮРё РәРҫРҪСӮРөРәСҒСӮ СӮРёСҒСҸСҮ СҒлів С– РҪавіСӮСҢ РІРёРәРҫРҪСғРІР°СӮРё завРҙР°РҪРҪСҸ, РҪР° СҸРәРёС… РІС–РҪ РҪРө РұСғРІ СҒРҝРөСҶіалСҢРҪРҫ РҪавСҮРөРҪРёР№.
ДлСҸ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ СҶС– РҙРҫСҒСҸРіРҪРөРҪРҪСҸ РҝРөСҖРөСӮРІРҫСҖилиСҒСҸ РҪР° СҮР°СӮ-РұРҫСӮС–РІ, СҸРәС– РјРҫгли:
РҹС–РҙСӮСҖРёРјСғРІР°СӮРё Р·РІ'СҸР·РҪС– СҖРҫР·РјРҫРІРё РҝСҖРҫСӮСҸРіРҫРј РұагаСӮСҢРҫС… РөСӮР°РҝС–РІ
Р РҫР·СғРјС–СӮРё РҪСҺР°РҪСҒРҫРІР°РҪС– Р·Р°РҝРёСӮРё РұРөР· СҒРҝРөСҶіалСҢРҪРҫРіРҫ РҪавСҮР°РҪРҪСҸ
Р“РөРҪРөСҖСғРІР°СӮРё СҖС–Р·РҪРҫРјР°РҪС–СӮРҪС–, РәРҫРҪСӮРөРәСҒСӮСғалСҢРҪРҫ РІС–РҙРҝРҫРІС–РҙРҪС– РІС–РҙРҝРҫРІС–РҙС–
РҗРҙР°РҝСӮСғРІР°СӮРё СҒРІС–Р№ СӮРҫРҪ С– СҒСӮРёР»СҢ РІС–РҙРҝРҫРІС–РҙРҪРҫ РҙРҫ РәРҫСҖРёСҒСӮСғРІР°СҮР°
РһРұСҖРҫРұР»СҸСӮРё РҪРөРҫРҙРҪРҫР·РҪР°СҮРҪС–СҒСӮСҢ СӮР° СғСӮРҫСҮРҪСҺРІР°СӮРё Р·Р° РҪРөРҫРұС…С–РҙРҪРҫСҒСӮС–
Р’РёРҝСғСҒРә ChatGPT РҪР°РҝСҖРёРәС–РҪСҶС– 2022 СҖРҫРәСғ Р·СҖРҫРұРёРІ СҶС– РјРҫжливРҫСҒСӮС– РҝРҫСҲРёСҖРөРҪРёРјРё, залСғСҮРёРІСҲРё РҝРҫРҪР°Рҙ РјС–Р»СҢР№РҫРҪ РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ РҝСҖРҫСӮСҸРіРҫРј РәС–Р»СҢРәРҫС… РҙРҪС–РІ РҝС–СҒР»СҸ Р·Р°РҝСғСҒРәСғ. Р Р°РҝСӮРҫРј СҲРёСҖРҫРәР° РіСҖРҫРјР°РҙСҒСҢРәС–СҒСӮСҢ РҫСӮСҖимала РҙРҫСҒСӮСғРҝ РҙРҫ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ, СҸРәРёР№ Р·РҙававСҒСҸ СҸРәС–СҒРҪРҫ РІС–РҙРјС–РҪРҪРёРј РІС–Рҙ СғСҒСҢРҫРіРҫ, СүРҫ РұСғР»Рҫ СҖР°РҪС–СҲРө вҖ“ РұС–Р»СҢСҲ РіРҪСғСҮРәРёРј, РұС–Р»СҢСҲ РҫРұС–Р·РҪР°РҪРёРј СӮР° РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРёРј Сғ СҒРІРҫС—Р№ взаємРҫРҙС–С—.
РҡРҫРјРөСҖСҶС–Р№РҪС– РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҲРІРёРҙРәРҫ РІС–РҙРұСғлиСҒСҸ, С– РәРҫРјРҝР°РҪС–С— РҝРҫСҮали РІРҝСҖРҫРІР°РҙР¶СғРІР°СӮРё РІРөлиРәС– РјРҫРІРҪС– РјРҫРҙРөлі Сғ СҒРІРҫС— РҝлаСӮС„РҫСҖРјРё РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ, С–РҪСҒСӮСҖСғРјРөРҪСӮРё РҙР»СҸ СҒСӮРІРҫСҖРөРҪРҪСҸ РәРҫРҪСӮРөРҪСӮСғ СӮР° РҝСҖРҫРіСҖами РҙР»СҸ РҝС–РҙРІРёСүРөРҪРҪСҸ РҝСҖРҫРҙСғРәСӮРёРІРҪРҫСҒСӮС–. РЁРІРёРҙРәРө РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ РІС–РҙРҫРұСҖажалРҫ СҸРә СӮРөС…РҪРҫР»РҫРіС–СҮРҪРёР№ СҒСӮСҖРёРұРҫРә, СӮР°Рә С– С–РҪСӮСғС—СӮРёРІРҪРҫ Р·СҖРҫР·Сғмілий С–РҪСӮРөСҖС„РөР№СҒ, СҸРәРёР№ РҪР°Рҙавали СҶС– РјРҫРҙРөлі вҖ“ Р·СҖРөСҲСӮРҫСҺ, СҖРҫР·РјРҫРІР° вҖ“ СҶРө РҪайРҝСҖРёСҖРҫРҙРҪС–СҲРёР№ СҒРҝРҫСҒС–Рұ СҒРҝС–Р»РәСғРІР°РҪРҪСҸ Р»СҺРҙРөР№.
РҹСҖРҫСӮРөСҒСӮСғР№СӮРө Р’РҗРЁ БізРҪРөСҒ Р·Р° РҘвилиРҪ
РЎСӮРІРҫСҖС–СӮСҢ РҫРұліРәРҫРІРёР№ Р·Р°РҝРёСҒ С– Р·Р°РҝСғСҒСӮС–СӮСҢ СҒРІРҫРіРҫ AI-СҮР°СӮРұРҫСӮР° Р·Р° ліСҮРөРҪС– хвилиРҪРё. РҹРҫРІРҪС–СҒСӮСҺ РҪалаСҲСӮРҫРІСғС”СӮСҢСҒСҸ, РұРөР· РҪРөРҫРұС…С–РҙРҪРҫСҒСӮС– РәРҫРҙСғРІР°РҪРҪСҸ - РҝРҫСҮРҪС–СӮСҢ залСғСҮР°СӮРё СҒРІРҫС—С… РәлієРҪСӮС–РІ РјРёСӮСӮєвРҫ!
Р“РҫСӮРҫРІРҫ Р·Р° хвилиРҪРё
Р‘РөР· РҝСҖРҫРіСҖамСғРІР°РҪРҪСҸ
100% РұРөР·РҝРөСҮРҪРҫ
РңСғР»СҢСӮРёРјРҫРҙалСҢРҪС– РјРҫжливРҫСҒСӮС–: РұС–Р»СҢСҲРө, РҪС–Р¶ РҝСҖРҫСҒСӮРҫ СӮРөРәСҒСӮРҫРІС– СҖРҫР·РјРҫРІРё
РҘРҫСҮР° СӮРөРәСҒСӮ РҙРҫРјС–РҪСғвав Сғ СҖРҫР·РІРёСӮРәСғ СҖРҫР·РјРҫРІРҪРҫРіРҫ СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ, РҫСҒСӮР°РҪРҪС–РјРё СҖРҫРәами СҒРҝРҫСҒСӮРөСҖігаєСӮСҢСҒСҸ РҝРҫСҲСӮРҫРІС… РҙРҫ РјСғР»СҢСӮРёРјРҫРҙалСҢРҪРёС… СҒРёСҒСӮРөРј, СҸРәС– РјРҫР¶СғСӮСҢ СҖРҫР·СғРјС–СӮРё СӮР° РіРөРҪРөСҖСғРІР°СӮРё СҖС–Р·РҪС– СӮРёРҝРё РјРөРҙС–Р°. РҰСҸ РөРІРҫР»СҺСҶС–СҸ РІС–РҙРҫРұСҖажає С„СғРҪРҙамРөРҪСӮалСҢРҪСғ С–СҒСӮРёРҪСғ РҝСҖРҫ Р»СҺРҙСҒСҢРәРө СҒРҝС–Р»РәСғРІР°РҪРҪСҸ вҖ“ РјРё РҪРө РҝСҖРҫСҒСӮРҫ РІРёРәРҫСҖРёСҒСӮРҫРІСғємРҫ СҒР»РҫРІР°; РјРё Р¶РөСҒСӮРёРәСғР»СҺємРҫ, РҝРҫРәазСғємРҫ Р·РҫРұСҖажРөРҪРҪСҸ, малСҺємРҫ РҙіагСҖами СӮР° РІРёРәРҫСҖРёСҒСӮРҫРІСғємРҫ РҪР°СҲРө СҒРөСҖРөРҙРҫРІРёСүРө РҙР»СҸ РҝРөСҖРөРҙР°СҮС– Р·РҪР°СҮРөРҪРҪСҸ.
РңРҫРҙРөлі РІС–Р·СғалСҢРҪРҫС— РјРҫРІРё, СӮР°РәС– СҸРә DALL-E, Midjourney СӮР° Stable Diffusion, РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖСғвали Р·РҙР°СӮРҪС–СҒСӮСҢ РіРөРҪРөСҖСғРІР°СӮРё Р·РҫРұСҖажРөРҪРҪСҸ Р· СӮРөРәСҒСӮРҫРІРёС… РҫРҝРёСҒС–РІ, СӮРҫРҙС– СҸРә РјРҫРҙРөлі, СӮР°РәС– СҸРә GPT-4, Р· РјРҫжливРҫСҒСӮСҸРјРё Р·РҫСҖСғ, РјРҫгли Р°РҪалізСғРІР°СӮРё Р·РҫРұСҖажРөРҪРҪСҸ СӮР° С–РҪСӮРөР»РөРәСӮСғалСҢРҪРҫ С—С… РҫРұРіРҫРІРҫСҖСҺРІР°СӮРё. РҰРө РІС–РҙРәСҖРёР»Рҫ РҪРҫРІС– РјРҫжливРҫСҒСӮС– РҙР»СҸ СҖРҫР·РјРҫРІРҪРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ:
Р‘РҫСӮРё СҒР»СғР¶РұРё РҝС–РҙСӮСҖРёРјРәРё РәлієРҪСӮС–РІ, СҸРәС– РјРҫР¶СғСӮСҢ Р°РҪалізСғРІР°СӮРё С„РҫСӮРҫРіСҖафії РҝРҫСҲРәРҫРҙР¶РөРҪРёС… СӮРҫРІР°СҖС–РІ
РҡРҫРҪСҒСғР»СҢСӮР°РҪСӮРё Р· РҝСҖРҫРҙажСғ, СҸРәС– РјРҫР¶СғСӮСҢ С–РҙРөРҪСӮифіРәСғРІР°СӮРё СӮРҫРІР°СҖРё Р·Р° Р·РҫРұСҖажРөРҪРҪСҸРјРё СӮР° Р·РҪахРҫРҙРёСӮРё СҒС…Рҫжі СӮРҫРІР°СҖРё
РһСҒРІС–СӮРҪС– С–РҪСҒСӮСҖСғРјРөРҪСӮРё, СҸРәС– РјРҫР¶СғСӮСҢ РҝРҫСҸСҒРҪСҺРІР°СӮРё РҙіагСҖами СӮР° РІС–Р·СғалСҢРҪС– РәРҫРҪСҶРөРҝСҶС–С—
РӨСғРҪРәСҶС–С— РҙРҫСҒСӮСғРҝРҪРҫСҒСӮС–, СҸРәС– РјРҫР¶СғСӮСҢ РҫРҝРёСҒСғРІР°СӮРё Р·РҫРұСҖажРөРҪРҪСҸ РҙР»СҸ РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ Р· РІР°Рҙами Р·РҫСҖСғ
Р“РҫР»РҫСҒРҫРІС– РјРҫжливРҫСҒСӮС– СӮР°РәРҫР¶ Р·РҪР°СҮРҪРҫ СҖРҫР·РІРёРҪСғлиСҒСҸ. Р Р°РҪРҪС– РјРҫРІРҪС– С–РҪСӮРөСҖС„РөР№СҒРё, СӮР°РәС– СҸРә СҒРёСҒСӮРөРјРё IVR (С–РҪСӮРөСҖР°РәСӮРёРІРҪРҫРіРҫ РіРҫР»РҫСҒРҫРІРҫРіРҫ СҖРөагСғРІР°РҪРҪСҸ), РұСғли, СҸРә РІС–РҙРҫРјРҫ, СҒРәлаРҙРҪРёРјРё, РҫРұРјРөР¶РөРҪРёРјРё Р¶РҫСҖСҒСӮРәРёРјРё РәРҫРјР°РҪРҙами СӮР° СҒСӮСҖСғРәСӮСғСҖами РјРөРҪСҺ. РЎСғСҮР°СҒРҪС– РіРҫР»РҫСҒРҫРІС– РҝРҫРјС–СҮРҪРёРәРё РјРҫР¶СғСӮСҢ СҖРҫР·СғРјС–СӮРё РҝСҖРёСҖРҫРҙРҪС– РјРҫРІР»РөРҪРҪєві РҝР°СӮРөСҖРҪРё, РІСҖахРҫРІСғРІР°СӮРё СҖС–Р·РҪС– Р°РәСҶРөРҪСӮРё СӮР° РІР°РҙРё РјРҫРІР»РөРҪРҪСҸ, Р° СӮР°РәРҫР¶ СҖРөагСғРІР°СӮРё РІСҒРө РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРёРјРё СҒРёРҪСӮРөР·РҫРІР°РҪРёРјРё РіРҫР»РҫСҒами. РҹРҫС”РҙРҪР°РҪРҪСҸ СҶРёС… РјРҫжливРҫСҒСӮРөР№ СҒСӮРІРҫСҖСҺС” СҒРҝСҖавРҙС– РјСғР»СҢСӮРёРјРҫРҙалСҢРҪРёР№ СҖРҫР·РјРҫРІРҪРёР№ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ, СҸРәРёР№ РјРҫР¶Рө РұРөР·РҝРөСҖРөСҲРәРҫРҙРҪРҫ РҝРөСҖРөРјРёРәР°СӮРёСҒСҸ РјС–Р¶ СҖС–Р·РҪРёРјРё СҖРөжимами СҒРҝС–Р»РәСғРІР°РҪРҪСҸ залРөР¶РҪРҫ РІС–Рҙ РәРҫРҪСӮРөРәСҒСӮСғ СӮР° РҝРҫСӮСҖРөРұ РәРҫСҖРёСҒСӮСғРІР°СҮР°. РҡРҫСҖРёСҒСӮСғРІР°СҮ РјРҫР¶Рө РҝРҫСҮР°СӮРё Р· СӮРөРәСҒСӮРҫРІРҫРіРҫ Р·Р°РҝРёСӮР°РҪРҪСҸ РҝСҖРҫ СҖРөРјРҫРҪСӮ РҝСҖРёРҪСӮРөСҖР°, РҪР°РҙС–СҒлаСӮРё С„РҫСӮРҫРіСҖафіСҺ РҝРҫРІС–РҙРҫРјР»РөРҪРҪСҸ РҝСҖРҫ РҝРҫРјРёР»РәСғ, РҫСӮСҖРёРјР°СӮРё СҒС…РөРјСғ Р· РІРёРҙС–Р»РөРҪРҪСҸРј РІС–РҙРҝРҫРІС–РҙРҪРёС… РәРҪРҫРҝРҫРә, Р° РҝРҫСӮС–Рј РҝРөСҖРөР№СӮРё РҙРҫ РіРҫР»РҫСҒРҫРІРёС… С–РҪСҒСӮСҖСғРәСҶС–Р№, РҝРҫРәРё Р№РҫРіРҫ СҖСғРәРё зайРҪСҸСӮС– СҖРөРјРҫРҪСӮРҫРј. РҰРөР№ РјСғР»СҢСӮРёРјРҫРҙалСҢРҪРёР№ РҝС–РҙС…С–Рҙ СҸРІР»СҸС” СҒРҫРұРҫСҺ РҪРө РҝСҖРҫСҒСӮРҫ СӮРөС…РҪС–СҮРҪРёР№ РҝСҖРҫРіСҖРөСҒ, Р° С„СғРҪРҙамРөРҪСӮалСҢРҪРёР№ Р·СҒСғРІ РҙРҫ РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРҫС— взаємРҫРҙС–С— Р»СҺРҙРёРҪРё Р· РәРҫРјРҝ'СҺСӮРөСҖРҫРј вҖ“ Р·СғСҒСӮСҖС–СҮС– Р· РәРҫСҖРёСҒСӮСғРІР°СҮами РІ РұСғРҙСҢ-СҸРәРҫРјСғ СҖРөжимі СҒРҝС–Р»РәСғРІР°РҪРҪСҸ, СҸРәРёР№ РҪайРәСҖР°СүРө РҝС–РҙС…РҫРҙРёСӮСҢ РҙР»СҸ С—С…РҪСҢРҫРіРҫ РҝРҫСӮРҫСҮРҪРҫРіРҫ РәРҫРҪСӮРөРәСҒСӮСғ СӮР° РҝРҫСӮСҖРөРұ.
РңРҫРҙРөлі РІС–Р·СғалСҢРҪРҫС— РјРҫРІРё, СӮР°РәС– СҸРә DALL-E, Midjourney СӮР° Stable Diffusion, РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖСғвали Р·РҙР°СӮРҪС–СҒСӮСҢ РіРөРҪРөСҖСғРІР°СӮРё Р·РҫРұСҖажРөРҪРҪСҸ Р· СӮРөРәСҒСӮРҫРІРёС… РҫРҝРёСҒС–РІ, СӮРҫРҙС– СҸРә РјРҫРҙРөлі, СӮР°РәС– СҸРә GPT-4, Р· РјРҫжливРҫСҒСӮСҸРјРё Р·РҫСҖСғ, РјРҫгли Р°РҪалізСғРІР°СӮРё Р·РҫРұСҖажРөРҪРҪСҸ СӮР° С–РҪСӮРөР»РөРәСӮСғалСҢРҪРҫ С—С… РҫРұРіРҫРІРҫСҖСҺРІР°СӮРё. РҰРө РІС–РҙРәСҖРёР»Рҫ РҪРҫРІС– РјРҫжливРҫСҒСӮС– РҙР»СҸ СҖРҫР·РјРҫРІРҪРёС… С–РҪСӮРөСҖС„РөР№СҒС–РІ:
Р‘РҫСӮРё СҒР»СғР¶РұРё РҝС–РҙСӮСҖРёРјРәРё РәлієРҪСӮС–РІ, СҸРәС– РјРҫР¶СғСӮСҢ Р°РҪалізСғРІР°СӮРё С„РҫСӮРҫРіСҖафії РҝРҫСҲРәРҫРҙР¶РөРҪРёС… СӮРҫРІР°СҖС–РІ
РҡРҫРҪСҒСғР»СҢСӮР°РҪСӮРё Р· РҝСҖРҫРҙажСғ, СҸРәС– РјРҫР¶СғСӮСҢ С–РҙРөРҪСӮифіРәСғРІР°СӮРё СӮРҫРІР°СҖРё Р·Р° Р·РҫРұСҖажРөРҪРҪСҸРјРё СӮР° Р·РҪахРҫРҙРёСӮРё СҒС…Рҫжі СӮРҫРІР°СҖРё
РһСҒРІС–СӮРҪС– С–РҪСҒСӮСҖСғРјРөРҪСӮРё, СҸРәС– РјРҫР¶СғСӮСҢ РҝРҫСҸСҒРҪСҺРІР°СӮРё РҙіагСҖами СӮР° РІС–Р·СғалСҢРҪС– РәРҫРҪСҶРөРҝСҶС–С—
РӨСғРҪРәСҶС–С— РҙРҫСҒСӮСғРҝРҪРҫСҒСӮС–, СҸРәС– РјРҫР¶СғСӮСҢ РҫРҝРёСҒСғРІР°СӮРё Р·РҫРұСҖажРөРҪРҪСҸ РҙР»СҸ РәРҫСҖРёСҒСӮСғРІР°СҮС–РІ Р· РІР°Рҙами Р·РҫСҖСғ
Р“РҫР»РҫСҒРҫРІС– РјРҫжливРҫСҒСӮС– СӮР°РәРҫР¶ Р·РҪР°СҮРҪРҫ СҖРҫР·РІРёРҪСғлиСҒСҸ. Р Р°РҪРҪС– РјРҫРІРҪС– С–РҪСӮРөСҖС„РөР№СҒРё, СӮР°РәС– СҸРә СҒРёСҒСӮРөРјРё IVR (С–РҪСӮРөСҖР°РәСӮРёРІРҪРҫРіРҫ РіРҫР»РҫСҒРҫРІРҫРіРҫ СҖРөагСғРІР°РҪРҪСҸ), РұСғли, СҸРә РІС–РҙРҫРјРҫ, СҒРәлаРҙРҪРёРјРё, РҫРұРјРөР¶РөРҪРёРјРё Р¶РҫСҖСҒСӮРәРёРјРё РәРҫРјР°РҪРҙами СӮР° СҒСӮСҖСғРәСӮСғСҖами РјРөРҪСҺ. РЎСғСҮР°СҒРҪС– РіРҫР»РҫСҒРҫРІС– РҝРҫРјС–СҮРҪРёРәРё РјРҫР¶СғСӮСҢ СҖРҫР·СғРјС–СӮРё РҝСҖРёСҖРҫРҙРҪС– РјРҫРІР»РөРҪРҪєві РҝР°СӮРөСҖРҪРё, РІСҖахРҫРІСғРІР°СӮРё СҖС–Р·РҪС– Р°РәСҶРөРҪСӮРё СӮР° РІР°РҙРё РјРҫРІР»РөРҪРҪСҸ, Р° СӮР°РәРҫР¶ СҖРөагСғРІР°СӮРё РІСҒРө РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРёРјРё СҒРёРҪСӮРөР·РҫРІР°РҪРёРјРё РіРҫР»РҫСҒами. РҹРҫС”РҙРҪР°РҪРҪСҸ СҶРёС… РјРҫжливРҫСҒСӮРөР№ СҒСӮРІРҫСҖСҺС” СҒРҝСҖавРҙС– РјСғР»СҢСӮРёРјРҫРҙалСҢРҪРёР№ СҖРҫР·РјРҫРІРҪРёР№ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ, СҸРәРёР№ РјРҫР¶Рө РұРөР·РҝРөСҖРөСҲРәРҫРҙРҪРҫ РҝРөСҖРөРјРёРәР°СӮРёСҒСҸ РјС–Р¶ СҖС–Р·РҪРёРјРё СҖРөжимами СҒРҝС–Р»РәСғРІР°РҪРҪСҸ залРөР¶РҪРҫ РІС–Рҙ РәРҫРҪСӮРөРәСҒСӮСғ СӮР° РҝРҫСӮСҖРөРұ РәРҫСҖРёСҒСӮСғРІР°СҮР°. РҡРҫСҖРёСҒСӮСғРІР°СҮ РјРҫР¶Рө РҝРҫСҮР°СӮРё Р· СӮРөРәСҒСӮРҫРІРҫРіРҫ Р·Р°РҝРёСӮР°РҪРҪСҸ РҝСҖРҫ СҖРөРјРҫРҪСӮ РҝСҖРёРҪСӮРөСҖР°, РҪР°РҙС–СҒлаСӮРё С„РҫСӮРҫРіСҖафіСҺ РҝРҫРІС–РҙРҫРјР»РөРҪРҪСҸ РҝСҖРҫ РҝРҫРјРёР»РәСғ, РҫСӮСҖРёРјР°СӮРё СҒС…РөРјСғ Р· РІРёРҙС–Р»РөРҪРҪСҸРј РІС–РҙРҝРҫРІС–РҙРҪРёС… РәРҪРҫРҝРҫРә, Р° РҝРҫСӮС–Рј РҝРөСҖРөР№СӮРё РҙРҫ РіРҫР»РҫСҒРҫРІРёС… С–РҪСҒСӮСҖСғРәСҶС–Р№, РҝРҫРәРё Р№РҫРіРҫ СҖСғРәРё зайРҪСҸСӮС– СҖРөРјРҫРҪСӮРҫРј. РҰРөР№ РјСғР»СҢСӮРёРјРҫРҙалСҢРҪРёР№ РҝС–РҙС…С–Рҙ СҸРІР»СҸС” СҒРҫРұРҫСҺ РҪРө РҝСҖРҫСҒСӮРҫ СӮРөС…РҪС–СҮРҪРёР№ РҝСҖРҫРіСҖРөСҒ, Р° С„СғРҪРҙамРөРҪСӮалСҢРҪРёР№ Р·СҒСғРІ РҙРҫ РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРҫС— взаємРҫРҙС–С— Р»СҺРҙРёРҪРё Р· РәРҫРјРҝ'СҺСӮРөСҖРҫРј вҖ“ Р·СғСҒСӮСҖС–СҮС– Р· РәРҫСҖРёСҒСӮСғРІР°СҮами РІ РұСғРҙСҢ-СҸРәРҫРјСғ СҖРөжимі СҒРҝС–Р»РәСғРІР°РҪРҪСҸ, СҸРәРёР№ РҪайРәСҖР°СүРө РҝС–РҙС…РҫРҙРёСӮСҢ РҙР»СҸ С—С…РҪСҢРҫРіРҫ РҝРҫСӮРҫСҮРҪРҫРіРҫ РәРҫРҪСӮРөРәСҒСӮСғ СӮР° РҝРҫСӮСҖРөРұ.
Р“РөРҪРөСҖР°СҶС–СҸ Р· РҙРҫРҝРҫРІРҪРөРҪРёРј РҝРҫСҲСғРәРҫРј: РҫРұТ‘СҖСғРҪСӮСғРІР°РҪРҪСҸ РЁРҶ фаРәСӮами
РқРөзважаСҺСҮРё РҪР° СҒРІРҫС— РІСҖажаСҺСҮС– РјРҫжливРҫСҒСӮС–, РІРөлиРәС– РјРҫРІРҪС– РјРҫРҙРөлі РјР°СҺСӮСҢ РҝСҖРёСӮамаРҪРҪС– РҫРұРјРөР¶РөРҪРҪСҸ. Р’РҫРҪРё РјРҫР¶СғСӮСҢ «галСҺСҶРёРҪСғРІР°СӮРёВ» С–РҪС„РҫСҖРјР°СҶС–СҺ, РІРҝРөРІРҪРөРҪРҫ Р·Р°СҸРІР»СҸСҺСҮРё РҝСҖавРҙРҫРҝРҫРҙС–РұРҪС–, алРө РҪРөРҝСҖавилСҢРҪС– фаРәСӮРё. РҮС…РҪС– Р·РҪР°РҪРҪСҸ РҫРұРјРөР¶РөРҪС– СӮРёРј, СүРҫ РұСғР»Рҫ РІ С—С…РҪС–С… РҪавСҮалСҢРҪРёС… РҙР°РҪРёС…, СүРҫ СҒСӮРІРҫСҖСҺС” РәС–РҪСҶРөРІРёР№ СӮРөСҖРјС–РҪ РҫСӮСҖРёРјР°РҪРҪСҸ Р·РҪР°РҪСҢ. РҶ РІРҫРҪРё РҪРө РјР°СҺСӮСҢ РјРҫжливРҫСҒСӮС– РҙРҫСҒСӮСғРҝСғ РҙРҫ С–РҪС„РҫСҖРјР°СҶС–С— РІ СҖРөжимі СҖРөалСҢРҪРҫРіРҫ СҮР°СҒСғ Р°РұРҫ СҒРҝРөСҶіалізРҫРІР°РҪРёС… Рұаз РҙР°РҪРёС…, СҸРәСүРҫ РІРҫРҪРё СҒРҝРөСҶіалСҢРҪРҫ РҪРө СҖРҫР·СҖРҫРұР»РөРҪС– РҙР»СҸ СҶСҢРҫРіРҫ.
Р РөС”СҒСӮСҖР°СҶС–Р№РҪРҫ-РҙРҫРҝРҫРІРҪРөРҪР° РіРөРҪРөСҖР°СҶС–СҸ (RAG) Р·'СҸвилаСҒСҸ СҸРә СҖС–СҲРөРҪРҪСҸ СҶРёС… РҝСҖРҫРұР»РөРј. ЗаміСҒСӮСҢ СӮРҫРіРҫ, СүРҫРұ РҝРҫРәлаРҙР°СӮРёСҒСҸ РІРёРәР»СҺСҮРҪРҫ РҪР° РҝР°СҖамРөСӮСҖРё, РІРёРІСҮРөРҪС– РҝС–Рҙ СҮР°СҒ РҪавСҮР°РҪРҪСҸ, СҒРёСҒСӮРөРјРё RAG РҝРҫС”РҙРҪСғСҺСӮСҢ РіРөРҪРөСҖР°СӮРёРІРҪС– РјРҫжливРҫСҒСӮС– РјРҫРІРҪРёС… РјРҫРҙРөР»РөР№ Р· РјРөС…Р°РҪізмами РҝРҫСҲСғРәСғ, СҸРәС– РјРҫР¶СғСӮСҢ РҫСӮСҖРёРјСғРІР°СӮРё РҙРҫСҒСӮСғРҝ РҙРҫ Р·РҫРІРҪС–СҲРҪС–С… РҙР¶РөСҖРөР» Р·РҪР°РҪСҢ.
РўРёРҝРҫРІР° Р°СҖС…С–СӮРөРәСӮСғСҖР° RAG РҝСҖР°СҶСҺС” СӮР°Рә:
РЎРёСҒСӮРөРјР° РҫСӮСҖРёРјСғС” Р·Р°РҝРёСӮ РәРҫСҖРёСҒСӮСғРІР°СҮР°
Р’РҫРҪР° СҲСғРәає С–РҪС„РҫСҖРјР°СҶС–СҺ, СүРҫ СҒСӮРҫСҒСғС”СӮСҢСҒСҸ Р·Р°РҝРёСӮСғ, Сғ РІС–РҙРҝРҫРІС–РҙРҪРёС… Рұазах Р·РҪР°РҪСҢ
Р’РҫРҪР° РҝРөСҖРөРҙає СҸРә Р·Р°РҝРёСӮ, СӮР°Рә С– РҫСӮСҖРёРјР°РҪСғ С–РҪС„РҫСҖРјР°СҶС–СҺ РҙРҫ РјРҫРІРҪРҫС— РјРҫРҙРөлі
РңРҫРҙРөР»СҢ РіРөРҪРөСҖСғС” РІС–РҙРҝРҫРІС–РҙСҢ, СүРҫ Т‘СҖСғРҪСӮСғС”СӮСҢСҒСҸ РҪР° РҫСӮСҖРёРјР°РҪРёС… фаРәСӮах
РҰРөР№ РҝС–РҙС…С–Рҙ РҝСҖРҫРҝРҫРҪСғС” РәС–Р»СҢРәР° РҝРөСҖРөваг:
БілСҢСҲ СӮРҫСҮРҪС–, фаРәСӮРёСҮРҪС– РІС–РҙРҝРҫРІС–РҙС– завРҙСҸРәРё РіРөРҪРөСҖР°СҶС–С— РҪР° РҫСҒРҪРҫРІС– РҝРөСҖРөРІС–СҖРөРҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С—
РңРҫжливіСҒСӮСҢ РҙРҫСҒСӮСғРҝСғ РҙРҫ Р°РәСӮСғалСҢРҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С— РҝС–СҒР»СҸ Р·Р°РәС–РҪСҮРөРҪРҪСҸ ліміСӮСғ РҪавСҮР°РҪРҪСҸ РјРҫРҙРөлі
РЎРҝРөСҶіалізРҫРІР°РҪС– Р·РҪР°РҪРҪСҸ Р· РҝСҖРөРҙРјРөСӮРҪРҫ-РҫСҖС–С”РҪСӮРҫРІР°РҪРёС… РҙР¶РөСҖРөР», СӮР°РәРёС… СҸРә РҙРҫРәСғРјРөРҪСӮР°СҶС–СҸ РәРҫРјРҝР°РҪС–С—
РҹСҖРҫР·РҫСҖС–СҒСӮСҢ СӮР° Р°СӮСҖРёРұСғСҶС–СҸ СҲР»СҸС…РҫРј СҶРёСӮСғРІР°РҪРҪСҸ РҙР¶РөСҖРөР» С–РҪС„РҫСҖРјР°СҶС–С—
ДлСҸ РәРҫРјРҝР°РҪС–Р№, СүРҫ РІРҝСҖРҫРІР°РҙР¶СғСҺСӮСҢ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ, RAG РІРёСҸРІРёРІСҒСҸ РҫСҒРҫРұливРҫ СҶС–РҪРҪРёРј РҙР»СҸ РҙРҫРҙР°СӮРәС–РІ РҙР»СҸ РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ. РқР°РҝСҖРёРәлаРҙ, РұР°РҪРәС–РІСҒСҢРәРёР№ СҮР°СӮ-РұРҫСӮ РјРҫР¶Рө РҫСӮСҖРёРјР°СӮРё РҙРҫСҒСӮСғРҝ РҙРҫ РҫСҒСӮР°РҪРҪС–С… РҙРҫРәСғРјРөРҪСӮС–РІ РҝРҫліСӮРёРәРё, С–РҪС„РҫСҖРјР°СҶС–С— РҝСҖРҫ СҖахСғРҪРәРё СӮР° Р·Р°РҝРёСҒС–РІ СӮСҖР°РҪР·Р°РәСҶС–Р№, СүРҫРұ РҪР°РҙаваСӮРё СӮРҫСҮРҪС–, РҝРөСҖСҒРҫРҪалізРҫРІР°РҪС– РІС–РҙРҝРҫРІС–РҙС–, СҸРәС– РұСғли Рұ РҪРөРјРҫжливі Р· РҫРәСҖРөРјРҫСҺ РјРҫРІРҪРҫСҺ РјРҫРҙРөллСҺ.
ЕвРҫР»СҺСҶС–СҸ СҒРёСҒСӮРөРј RAG РҝСҖРҫРҙРҫРІР¶СғС”СӮСҢСҒСҸ Р· РҝРҫРәСҖР°СүРөРҪРҪСҸРј СӮРҫСҮРҪРҫСҒСӮС– РҝРҫСҲСғРәСғ, РұС–Р»СҢСҲ СҒРәлаРҙРҪРёРјРё РјРөСӮРҫРҙами С–РҪСӮРөРіСҖР°СҶС–С— РҫСӮСҖРёРјР°РҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С— Р·С– Р·РіРөРҪРөСҖРҫРІР°РҪРёРј СӮРөРәСҒСӮРҫРј СӮР° РәСҖР°СүРёРјРё РјРөС…Р°РҪізмами РҫСҶС–РҪРәРё РҪР°РҙС–Р№РҪРҫСҒСӮС– СҖС–Р·РҪРёС… РҙР¶РөСҖРөР» С–РҪС„РҫСҖРјР°СҶС–С—.
Р РөС”СҒСӮСҖР°СҶС–Р№РҪРҫ-РҙРҫРҝРҫРІРҪРөРҪР° РіРөРҪРөСҖР°СҶС–СҸ (RAG) Р·'СҸвилаСҒСҸ СҸРә СҖС–СҲРөРҪРҪСҸ СҶРёС… РҝСҖРҫРұР»РөРј. ЗаміСҒСӮСҢ СӮРҫРіРҫ, СүРҫРұ РҝРҫРәлаРҙР°СӮРёСҒСҸ РІРёРәР»СҺСҮРҪРҫ РҪР° РҝР°СҖамРөСӮСҖРё, РІРёРІСҮРөРҪС– РҝС–Рҙ СҮР°СҒ РҪавСҮР°РҪРҪСҸ, СҒРёСҒСӮРөРјРё RAG РҝРҫС”РҙРҪСғСҺСӮСҢ РіРөРҪРөСҖР°СӮРёРІРҪС– РјРҫжливРҫСҒСӮС– РјРҫРІРҪРёС… РјРҫРҙРөР»РөР№ Р· РјРөС…Р°РҪізмами РҝРҫСҲСғРәСғ, СҸРәС– РјРҫР¶СғСӮСҢ РҫСӮСҖРёРјСғРІР°СӮРё РҙРҫСҒСӮСғРҝ РҙРҫ Р·РҫРІРҪС–СҲРҪС–С… РҙР¶РөСҖРөР» Р·РҪР°РҪСҢ.
РўРёРҝРҫРІР° Р°СҖС…С–СӮРөРәСӮСғСҖР° RAG РҝСҖР°СҶСҺС” СӮР°Рә:
РЎРёСҒСӮРөРјР° РҫСӮСҖРёРјСғС” Р·Р°РҝРёСӮ РәРҫСҖРёСҒСӮСғРІР°СҮР°
Р’РҫРҪР° СҲСғРәає С–РҪС„РҫСҖРјР°СҶС–СҺ, СүРҫ СҒСӮРҫСҒСғС”СӮСҢСҒСҸ Р·Р°РҝРёСӮСғ, Сғ РІС–РҙРҝРҫРІС–РҙРҪРёС… Рұазах Р·РҪР°РҪСҢ
Р’РҫРҪР° РҝРөСҖРөРҙає СҸРә Р·Р°РҝРёСӮ, СӮР°Рә С– РҫСӮСҖРёРјР°РҪСғ С–РҪС„РҫСҖРјР°СҶС–СҺ РҙРҫ РјРҫРІРҪРҫС— РјРҫРҙРөлі
РңРҫРҙРөР»СҢ РіРөРҪРөСҖСғС” РІС–РҙРҝРҫРІС–РҙСҢ, СүРҫ Т‘СҖСғРҪСӮСғС”СӮСҢСҒСҸ РҪР° РҫСӮСҖРёРјР°РҪРёС… фаРәСӮах
РҰРөР№ РҝС–РҙС…С–Рҙ РҝСҖРҫРҝРҫРҪСғС” РәС–Р»СҢРәР° РҝРөСҖРөваг:
БілСҢСҲ СӮРҫСҮРҪС–, фаРәСӮРёСҮРҪС– РІС–РҙРҝРҫРІС–РҙС– завРҙСҸРәРё РіРөРҪРөСҖР°СҶС–С— РҪР° РҫСҒРҪРҫРІС– РҝРөСҖРөРІС–СҖРөРҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С—
РңРҫжливіСҒСӮСҢ РҙРҫСҒСӮСғРҝСғ РҙРҫ Р°РәСӮСғалСҢРҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С— РҝС–СҒР»СҸ Р·Р°РәС–РҪСҮРөРҪРҪСҸ ліміСӮСғ РҪавСҮР°РҪРҪСҸ РјРҫРҙРөлі
РЎРҝРөСҶіалізРҫРІР°РҪС– Р·РҪР°РҪРҪСҸ Р· РҝСҖРөРҙРјРөСӮРҪРҫ-РҫСҖС–С”РҪСӮРҫРІР°РҪРёС… РҙР¶РөСҖРөР», СӮР°РәРёС… СҸРә РҙРҫРәСғРјРөРҪСӮР°СҶС–СҸ РәРҫРјРҝР°РҪС–С—
РҹСҖРҫР·РҫСҖС–СҒСӮСҢ СӮР° Р°СӮСҖРёРұСғСҶС–СҸ СҲР»СҸС…РҫРј СҶРёСӮСғРІР°РҪРҪСҸ РҙР¶РөСҖРөР» С–РҪС„РҫСҖРјР°СҶС–С—
ДлСҸ РәРҫРјРҝР°РҪС–Р№, СүРҫ РІРҝСҖРҫРІР°РҙР¶СғСҺСӮСҢ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ, RAG РІРёСҸРІРёРІСҒСҸ РҫСҒРҫРұливРҫ СҶС–РҪРҪРёРј РҙР»СҸ РҙРҫРҙР°СӮРәС–РІ РҙР»СҸ РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ. РқР°РҝСҖРёРәлаРҙ, РұР°РҪРәС–РІСҒСҢРәРёР№ СҮР°СӮ-РұРҫСӮ РјРҫР¶Рө РҫСӮСҖРёРјР°СӮРё РҙРҫСҒСӮСғРҝ РҙРҫ РҫСҒСӮР°РҪРҪС–С… РҙРҫРәСғРјРөРҪСӮС–РІ РҝРҫліСӮРёРәРё, С–РҪС„РҫСҖРјР°СҶС–С— РҝСҖРҫ СҖахСғРҪРәРё СӮР° Р·Р°РҝРёСҒС–РІ СӮСҖР°РҪР·Р°РәСҶС–Р№, СүРҫРұ РҪР°РҙаваСӮРё СӮРҫСҮРҪС–, РҝРөСҖСҒРҫРҪалізРҫРІР°РҪС– РІС–РҙРҝРҫРІС–РҙС–, СҸРәС– РұСғли Рұ РҪРөРјРҫжливі Р· РҫРәСҖРөРјРҫСҺ РјРҫРІРҪРҫСҺ РјРҫРҙРөллСҺ.
ЕвРҫР»СҺСҶС–СҸ СҒРёСҒСӮРөРј RAG РҝСҖРҫРҙРҫРІР¶СғС”СӮСҢСҒСҸ Р· РҝРҫРәСҖР°СүРөРҪРҪСҸРј СӮРҫСҮРҪРҫСҒСӮС– РҝРҫСҲСғРәСғ, РұС–Р»СҢСҲ СҒРәлаРҙРҪРёРјРё РјРөСӮРҫРҙами С–РҪСӮРөРіСҖР°СҶС–С— РҫСӮСҖРёРјР°РҪРҫС— С–РҪС„РҫСҖРјР°СҶС–С— Р·С– Р·РіРөРҪРөСҖРҫРІР°РҪРёРј СӮРөРәСҒСӮРҫРј СӮР° РәСҖР°СүРёРјРё РјРөС…Р°РҪізмами РҫСҶС–РҪРәРё РҪР°РҙС–Р№РҪРҫСҒСӮС– СҖС–Р·РҪРёС… РҙР¶РөСҖРөР» С–РҪС„РҫСҖРјР°СҶС–С—.
РңРҫРҙРөР»СҢ СҒРҝС–РІРҝСҖР°СҶС– Р»СҺРҙРёРҪРё СӮР° СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ: РҝРҫСҲСғРә РҝСҖавилСҢРҪРҫРіРҫ РұалаРҪСҒСғ
Р— СҖРҫР·СҲРёСҖРөРҪРҪСҸРј РјРҫжливРҫСҒСӮРөР№ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ СҖРҫзвивалиСҒСҸ Р№ РІС–РҙРҪРҫСҒРёРҪРё РјС–Р¶ Р»СҺРҙСҢРјРё СӮР° СҒРёСҒСӮРөмами РЁРҶ. Р Р°РҪРҪС– СҮР°СӮ-РұРҫСӮРё СҮС–СӮРәРҫ РҝРҫР·РёСҶС–РҫРҪСғвалиСҒСҸ СҸРә С–РҪСҒСӮСҖСғРјРөРҪСӮРё вҖ“ РҫРұРјРөР¶РөРҪС– Р·Р° РҫРұСҒСҸРіРҫРј СӮР°, РҫСҮРөРІРёРҙРҪРҫ, РҪРөР»СҺРҙСҒСҢРәС– Сғ СҒРІРҫС—Р№ взаємРҫРҙС–С—. РЎСғСҮР°СҒРҪС– СҒРёСҒСӮРөРјРё СҖРҫР·РјРёРІР°СҺСӮСҢ СҶС– РјРөжі, СҒСӮРІРҫСҖСҺСҺСҮРё РҪРҫРІС– РҝРёСӮР°РҪРҪСҸ СүРҫРҙРҫ СӮРҫРіРҫ, СҸРә СҖРҫР·СҖРҫРұР»СҸСӮРё РөС„РөРәСӮРёРІРҪСғ СҒРҝС–РІРҝСҖР°СҶСҺ РјС–Р¶ Р»СҺРҙРёРҪРҫСҺ СӮР° РЁРҶ.
РқайСғСҒРҝС–СҲРҪС–СҲС– РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҒСҢРҫРіРҫРҙРҪС– РҙРҫСӮСҖРёРјСғСҺСӮСҢСҒСҸ РјРҫРҙРөлі СҒРҝС–РІРҝСҖР°СҶС–, РҙРө:
РЁРҶ РҫРұСҖРҫРұР»СҸС” СҖСғСӮРёРҪРҪС–, РҝРҫРІСӮРҫСҖСҺРІР°РҪС– Р·Р°РҝРёСӮРё, СҸРәС– РҪРө РҝРҫСӮСҖРөРұСғСҺСӮСҢ Р»СҺРҙСҒСҢРәРҫРіРҫ СҒСғРҙР¶РөРҪРҪСҸ.
РӣСҺРҙРё Р·РҫСҒРөСҖРөРҙР¶СғСҺСӮСҢСҒСҸ РҪР° СҒРәлаРҙРҪРёС… РІРёРҝР°РҙРәах, СүРҫ вимагаСҺСӮСҢ РөРјРҝР°СӮС–С—, РөСӮРёСҮРҪРёС… РјС–СҖРәСғРІР°РҪСҢ Р°РұРҫ СӮРІРҫСҖСҮРҫРіРҫ РІРёСҖС–СҲРөРҪРҪСҸ РҝСҖРҫРұР»РөРј.
РЎРёСҒСӮРөРјР° Р·РҪає СҒРІРҫС— РҫРұРјРөР¶РөРҪРҪСҸ СӮР° РҝлавРҪРҫ РҝРөСҖРөС…РҫРҙРёСӮСҢ РҙРҫ Р»СҺРҙСҒСҢРәРёС… агРөРҪСӮС–РІ, РәРҫли СҶРө РҙРҫСҖРөСҮРҪРҫ.
РҹРөСҖРөС…С–Рҙ РјС–Р¶ РЁРҶ СӮР° Р»СҺРҙСҒСҢРәРҫСҺ РҝС–РҙСӮСҖРёРјРәРҫСҺ С” РұРөР·РҝСҖРҫРұР»РөРјРҪРёРј РҙР»СҸ РәРҫСҖРёСҒСӮСғРІР°СҮР°.
РӣСҺРҙРё-агРөРҪСӮРё РјР°СҺСӮСҢ РҝРҫРІРҪРёР№ РәРҫРҪСӮРөРәСҒСӮ С–СҒСӮРҫСҖС–С— СҖРҫР·РјРҫРІ Р·С– РЁРҶ.
РЁРҶ РҝСҖРҫРҙРҫРІР¶СғС” РҪавСҮР°СӮРёСҒСҸ РҪР° Р»СҺРҙСҒСҢРәРҫРјСғ РІСӮСҖСғСҮР°РҪРҪС–, РҝРҫСҒСӮСғРҝРҫРІРҫ СҖРҫР·СҲРёСҖСҺСҺСҮРё СҒРІРҫС— РјРҫжливРҫСҒСӮС–.
РҰРөР№ РҝС–РҙС…С–Рҙ РІРёР·РҪає, СүРҫ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ РҪРө РҝРҫРІРёРҪРөРҪ РҝСҖагРҪСғСӮРё РҝРҫРІРҪС–СҒСӮСҺ заміРҪРёСӮРё Р»СҺРҙСҒСҢРәСғ взаємРҫРҙС–СҺ, Р° СҖР°РҙСҲРө РҙРҫРҝРҫРІРҪСҺРІР°СӮРё С—С— вҖ“ РҫРұСҖРҫРұР»СҸСӮРё РІРөлиРәРёР№ РҫРұСҒСҸРі, РҝСҖРҫСҒСӮС– Р·Р°РҝРёСӮРё, СҸРәС– СҒРҝРҫживаСҺСӮСҢ СҮР°СҒ Р»СҺРҙСҒСҢРәРёС… агРөРҪСӮС–РІ, РҫРҙРҪРҫСҮР°СҒРҪРҫ Р·Р°РұРөР·РҝРөСҮСғСҺСҮРё, СүРҫРұ СҒРәлаРҙРҪС– РҝРёСӮР°РҪРҪСҸ РҙРҫСҒСҸгли РҝРҫСӮСҖС–РұРҪРҫС— Р»СҺРҙСҒСҢРәРҫС— РөРәСҒРҝРөСҖСӮРёР·Рё.
Р’РҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҶієї РјРҫРҙРөлі РІР°СҖС–СҺС”СӮСҢСҒСҸ залРөР¶РҪРҫ РІС–Рҙ галСғР·С–. РЈ СҒС„РөСҖС– РҫС…РҫСҖРҫРҪРё Р·РҙРҫСҖРҫРІ'СҸ СҮР°СӮ-РұРҫСӮРё Р·С– СҲСӮСғСҮРҪРёРј С–РҪСӮРөР»РөРәСӮРҫРј РјРҫР¶СғСӮСҢ займаСӮРёСҒСҸ РҝлаРҪСғРІР°РҪРҪСҸРј Р·СғСҒСӮСҖС–СҮРөР№ СӮР° РұазРҫРІРёРј СҒРәСҖРёРҪС–РҪРіРҫРј СҒРёРјРҝСӮРҫРјС–РІ, РІРҫРҙРҪРҫСҮР°СҒ Р·Р°РұРөР·РҝРөСҮСғСҺСҮРё РјРөРҙРёСҮРҪС– РәРҫРҪСҒСғР»СҢСӮР°СҶС–С— РәваліфіРәРҫРІР°РҪРёРјРё фахівСҶСҸРјРё. РЈ СҺСҖРёРҙРёСҮРҪРёС… РҝРҫСҒР»Сғгах СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ РјРҫР¶Рө РҙРҫРҝРҫмагаСӮРё Р· РҝС–РҙРіРҫСӮРҫРІРәРҫСҺ РҙРҫРәСғРјРөРҪСӮС–РІ СӮР° РҙРҫСҒліРҙР¶РөРҪРҪСҸРј, залиСҲР°СҺСҮРё С–РҪСӮРөСҖРҝСҖРөСӮР°СҶС–СҺ СӮР° СҒСӮСҖР°СӮРөРіС–СҺ Р°РҙРІРҫРәР°СӮам. РЈ СҒС„РөСҖС– РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ РјРҫР¶Рө РІРёСҖС–СҲСғРІР°СӮРё РҝРҫСҲРёСҖРөРҪС– РҝСҖРҫРұР»РөРјРё, РҫРҙРҪРҫСҮР°СҒРҪРҫ РҝРөСҖРөРҪР°РҝСҖавлСҸСҺСҮРё СҒРәлаРҙРҪС– РҝСҖРҫРұР»РөРјРё СҒРҝРөСҶіалізРҫРІР°РҪРёРј агРөРҪСӮам.
Р— СҖРҫР·РІРёСӮРәРҫРј РјРҫжливРҫСҒСӮРөР№ СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ РјРөжа РјС–Р¶ СӮРёРј, СүРҫ вимагає СғСҮР°СҒСӮС– Р»СҺРҙРёРҪРё, С– СӮРёРј, СүРҫ РјРҫР¶РҪР° авСӮРҫРјР°СӮРёР·СғРІР°СӮРё, Р·РјС–СүСғРІР°СӮРёРјРөСӮСҢСҒСҸ, алРө С„СғРҪРҙамРөРҪСӮалСҢРҪРёР№ РҝСҖРёРҪСҶРёРҝ залиСҲаєСӮСҢСҒСҸ РҪРөР·РјС–РҪРҪРёРј: РөС„РөРәСӮРёРІРҪРёР№ СҖРҫР·РјРҫРІРҪРёР№ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ РҝРҫРІРёРҪРөРҪ РҝРҫРәСҖР°СүСғРІР°СӮРё Р»СҺРҙСҒСҢРәС– РјРҫжливРҫСҒСӮС–, Р° РҪРө РҝСҖРҫСҒСӮРҫ заміРҪСҺРІР°СӮРё С—С….
РқайСғСҒРҝС–СҲРҪС–СҲС– РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҒСҢРҫРіРҫРҙРҪС– РҙРҫСӮСҖРёРјСғСҺСӮСҢСҒСҸ РјРҫРҙРөлі СҒРҝС–РІРҝСҖР°СҶС–, РҙРө:
РЁРҶ РҫРұСҖРҫРұР»СҸС” СҖСғСӮРёРҪРҪС–, РҝРҫРІСӮРҫСҖСҺРІР°РҪС– Р·Р°РҝРёСӮРё, СҸРәС– РҪРө РҝРҫСӮСҖРөРұСғСҺСӮСҢ Р»СҺРҙСҒСҢРәРҫРіРҫ СҒСғРҙР¶РөРҪРҪСҸ.
РӣСҺРҙРё Р·РҫСҒРөСҖРөРҙР¶СғСҺСӮСҢСҒСҸ РҪР° СҒРәлаРҙРҪРёС… РІРёРҝР°РҙРәах, СүРҫ вимагаСҺСӮСҢ РөРјРҝР°СӮС–С—, РөСӮРёСҮРҪРёС… РјС–СҖРәСғРІР°РҪСҢ Р°РұРҫ СӮРІРҫСҖСҮРҫРіРҫ РІРёСҖС–СҲРөРҪРҪСҸ РҝСҖРҫРұР»РөРј.
РЎРёСҒСӮРөРјР° Р·РҪає СҒРІРҫС— РҫРұРјРөР¶РөРҪРҪСҸ СӮР° РҝлавРҪРҫ РҝРөСҖРөС…РҫРҙРёСӮСҢ РҙРҫ Р»СҺРҙСҒСҢРәРёС… агРөРҪСӮС–РІ, РәРҫли СҶРө РҙРҫСҖРөСҮРҪРҫ.
РҹРөСҖРөС…С–Рҙ РјС–Р¶ РЁРҶ СӮР° Р»СҺРҙСҒСҢРәРҫСҺ РҝС–РҙСӮСҖРёРјРәРҫСҺ С” РұРөР·РҝСҖРҫРұР»РөРјРҪРёРј РҙР»СҸ РәРҫСҖРёСҒСӮСғРІР°СҮР°.
РӣСҺРҙРё-агРөРҪСӮРё РјР°СҺСӮСҢ РҝРҫРІРҪРёР№ РәРҫРҪСӮРөРәСҒСӮ С–СҒСӮРҫСҖС–С— СҖРҫР·РјРҫРІ Р·С– РЁРҶ.
РЁРҶ РҝСҖРҫРҙРҫРІР¶СғС” РҪавСҮР°СӮРёСҒСҸ РҪР° Р»СҺРҙСҒСҢРәРҫРјСғ РІСӮСҖСғСҮР°РҪРҪС–, РҝРҫСҒСӮСғРҝРҫРІРҫ СҖРҫР·СҲРёСҖСҺСҺСҮРё СҒРІРҫС— РјРҫжливРҫСҒСӮС–.
РҰРөР№ РҝС–РҙС…С–Рҙ РІРёР·РҪає, СүРҫ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ РҪРө РҝРҫРІРёРҪРөРҪ РҝСҖагРҪСғСӮРё РҝРҫРІРҪС–СҒСӮСҺ заміРҪРёСӮРё Р»СҺРҙСҒСҢРәСғ взаємРҫРҙС–СҺ, Р° СҖР°РҙСҲРө РҙРҫРҝРҫРІРҪСҺРІР°СӮРё С—С— вҖ“ РҫРұСҖРҫРұР»СҸСӮРё РІРөлиРәРёР№ РҫРұСҒСҸРі, РҝСҖРҫСҒСӮС– Р·Р°РҝРёСӮРё, СҸРәС– СҒРҝРҫживаСҺСӮСҢ СҮР°СҒ Р»СҺРҙСҒСҢРәРёС… агРөРҪСӮС–РІ, РҫРҙРҪРҫСҮР°СҒРҪРҫ Р·Р°РұРөР·РҝРөСҮСғСҺСҮРё, СүРҫРұ СҒРәлаРҙРҪС– РҝРёСӮР°РҪРҪСҸ РҙРҫСҒСҸгли РҝРҫСӮСҖС–РұРҪРҫС— Р»СҺРҙСҒСҢРәРҫС— РөРәСҒРҝРөСҖСӮРёР·Рё.
Р’РҝСҖРҫРІР°РҙР¶РөРҪРҪСҸ СҶієї РјРҫРҙРөлі РІР°СҖС–СҺС”СӮСҢСҒСҸ залРөР¶РҪРҫ РІС–Рҙ галСғР·С–. РЈ СҒС„РөСҖС– РҫС…РҫСҖРҫРҪРё Р·РҙРҫСҖРҫРІ'СҸ СҮР°СӮ-РұРҫСӮРё Р·С– СҲСӮСғСҮРҪРёРј С–РҪСӮРөР»РөРәСӮРҫРј РјРҫР¶СғСӮСҢ займаСӮРёСҒСҸ РҝлаРҪСғРІР°РҪРҪСҸРј Р·СғСҒСӮСҖС–СҮРөР№ СӮР° РұазРҫРІРёРј СҒРәСҖРёРҪС–РҪРіРҫРј СҒРёРјРҝСӮРҫРјС–РІ, РІРҫРҙРҪРҫСҮР°СҒ Р·Р°РұРөР·РҝРөСҮСғСҺСҮРё РјРөРҙРёСҮРҪС– РәРҫРҪСҒСғР»СҢСӮР°СҶС–С— РәваліфіРәРҫРІР°РҪРёРјРё фахівСҶСҸРјРё. РЈ СҺСҖРёРҙРёСҮРҪРёС… РҝРҫСҒР»Сғгах СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ РјРҫР¶Рө РҙРҫРҝРҫмагаСӮРё Р· РҝС–РҙРіРҫСӮРҫРІРәРҫСҺ РҙРҫРәСғРјРөРҪСӮС–РІ СӮР° РҙРҫСҒліРҙР¶РөРҪРҪСҸРј, залиСҲР°СҺСҮРё С–РҪСӮРөСҖРҝСҖРөСӮР°СҶС–СҺ СӮР° СҒСӮСҖР°СӮРөРіС–СҺ Р°РҙРІРҫРәР°СӮам. РЈ СҒС„РөСҖС– РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ РјРҫР¶Рө РІРёСҖС–СҲСғРІР°СӮРё РҝРҫСҲРёСҖРөРҪС– РҝСҖРҫРұР»РөРјРё, РҫРҙРҪРҫСҮР°СҒРҪРҫ РҝРөСҖРөРҪР°РҝСҖавлСҸСҺСҮРё СҒРәлаРҙРҪС– РҝСҖРҫРұР»РөРјРё СҒРҝРөСҶіалізРҫРІР°РҪРёРј агРөРҪСӮам.
Р— СҖРҫР·РІРёСӮРәРҫРј РјРҫжливРҫСҒСӮРөР№ СҲСӮСғСҮРҪРҫРіРҫ С–РҪСӮРөР»РөРәСӮСғ РјРөжа РјС–Р¶ СӮРёРј, СүРҫ вимагає СғСҮР°СҒСӮС– Р»СҺРҙРёРҪРё, С– СӮРёРј, СүРҫ РјРҫР¶РҪР° авСӮРҫРјР°СӮРёР·СғРІР°СӮРё, Р·РјС–СүСғРІР°СӮРёРјРөСӮСҢСҒСҸ, алРө С„СғРҪРҙамРөРҪСӮалСҢРҪРёР№ РҝСҖРёРҪСҶРёРҝ залиСҲаєСӮСҢСҒСҸ РҪРөР·РјС–РҪРҪРёРј: РөС„РөРәСӮРёРІРҪРёР№ СҖРҫР·РјРҫРІРҪРёР№ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ РҝРҫРІРёРҪРөРҪ РҝРҫРәСҖР°СүСғРІР°СӮРё Р»СҺРҙСҒСҢРәС– РјРҫжливРҫСҒСӮС–, Р° РҪРө РҝСҖРҫСҒСӮРҫ заміРҪСҺРІР°СӮРё С—С….
РңайРұСғСӮРҪС”: РәСғРҙРё РҝСҖСҸРјСғС” СҖРҫР·РјРҫРІРҪРёР№ СҲСӮСғСҮРҪРёР№ С–РҪСӮРөР»РөРәСӮ
ДивлСҸСҮРёСҒСҢ Сғ майРұСғСӮРҪС”, РјРё РұР°СҮРёРјРҫ РәС–Р»СҢРәР° РҪРҫРІРёС… СӮРөРҪРҙРөРҪСҶС–Р№, СҸРәС– С„РҫСҖРјСғСҺСӮСҢ майРұСғСӮРҪС” СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ. РҰС– СҖРҫР·СҖРҫРұРәРё РҫРұС–СҶСҸСҺСӮСҢ РҪРө лиСҲРө РҝРҫСҒСӮСғРҝРҫРІС– РҝРҫРәСҖР°СүРөРҪРҪСҸ, Р° Р№ РҝРҫСӮРөРҪСҶС–Р№РҪРҫ СӮСҖР°РҪСҒС„РҫСҖРјР°СҶС–Р№РҪС– Р·РјС–РҪРё Сғ СӮРҫРјСғ, СҸРә РјРё взаємРҫРҙіємРҫ Р· СӮРөС…РҪРҫР»РҫРіС–СҸРјРё. РңР°СҒСҲСӮР°РұРҪР° РҝРөСҖСҒРҫРҪалізаСҶС–СҸ: РңайРұСғСӮРҪС– СҒРёСҒСӮРөРјРё РІСҒРө РұС–Р»СҢСҲРө Р°РҙР°РҝСӮСғРІР°СӮРёРјСғСӮСҢ СҒРІРҫС— СҖРөР°РәСҶС–С— РҪРө лиСҲРө РҙРҫ РұРөР·РҝРҫСҒРөСҖРөРҙРҪСҢРҫРіРҫ РәРҫРҪСӮРөРәСҒСӮСғ, алРө Р№ РҙРҫ СҒСӮРёР»СҺ СҒРҝС–Р»РәСғРІР°РҪРҪСҸ, СғРҝРҫРҙРҫРұР°РҪСҢ, СҖС–РІРҪСҸ Р·РҪР°РҪСҢ СӮР° С–СҒСӮРҫСҖС–С— СҒСӮРҫСҒСғРҪРәС–РІ РәРҫР¶РҪРҫРіРҫ РәРҫСҖРёСҒСӮСғРІР°СҮР°. РҰСҸ РҝРөСҖСҒРҫРҪалізаСҶС–СҸ Р·СҖРҫРұРёСӮСҢ взаємРҫРҙС–СҺ РұС–Р»СҢСҲ РҝСҖРёСҖРҫРҙРҪРҫСҺ СӮР° СҖРөР»РөРІР°РҪСӮРҪРҫСҺ, С…РҫСҮР° Р№ РҝРҫСҖСғСҲСғС” важливі РҝРёСӮР°РҪРҪСҸ СүРҫРҙРҫ РәРҫРҪфіРҙРөРҪСҶС–Р№РҪРҫСҒСӮС– СӮР° РІРёРәРҫСҖРёСҒСӮР°РҪРҪСҸ РҙР°РҪРёС…. ЕмРҫСҶС–Р№РҪРёР№ С–РҪСӮРөР»РөРәСӮ: РЈ СӮРҫР№ СҮР°СҒ СҸРә СҒСғСҮР°СҒРҪС– СҒРёСҒСӮРөРјРё РјРҫР¶СғСӮСҢ РІРёСҸРІР»СҸСӮРё РұазРҫРІС– РҪР°СҒСӮСҖРҫС—, майРұСғСӮРҪС–Р№ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ СҖРҫР·РІРёРҪРө РұС–Р»СҢСҲ СҒРәлаРҙРҪРёР№ РөРјРҫСҶС–Р№РҪРёР№ С–РҪСӮРөР»РөРәСӮ вҖ“ СҖРҫР·РҝС–Р·РҪаваСӮРёРјРө Р»РөРҙСҢ РҝРҫРјС–СӮРҪС– РөРјРҫСҶС–Р№РҪС– СҒСӮР°РҪРё, РІС–РҙРҝРҫРІС–РҙРҪРҫ СҖРөагСғРІР°СӮРёРјРө РҪР° СҒСӮСҖРөСҒ Р°РұРҫ СҖРҫР·СҮР°СҖСғРІР°РҪРҪСҸ СӮР° РІС–РҙРҝРҫРІС–РҙРҪРҫ Р°РҙР°РҝСӮСғРІР°СӮРёРјРө СҒРІС–Р№ СӮРҫРҪ С– РҝС–РҙС…С–Рҙ. РҰСҸ Р·РҙР°СӮРҪС–СҒСӮСҢ РұСғРҙРө РҫСҒРҫРұливРҫ СҶС–РҪРҪРҫСҺ РІ СҒС„РөСҖах РҫРұСҒР»СғРіРҫРІСғРІР°РҪРҪСҸ РәлієРҪСӮС–РІ, РҫС…РҫСҖРҫРҪРё Р·РҙРҫСҖРҫРІ'СҸ СӮР° РҫСҒРІС–СӮРё. РҹСҖРҫР°РәСӮРёРІРҪР° РҙРҫРҝРҫРјРҫРіР°: ЗаміСҒСӮСҢ СӮРҫРіРҫ, СүРҫРұ СҮРөРәР°СӮРё РҪР° СҸРІРҪС– Р·Р°РҝРёСӮРё, СҖРҫР·РјРҫРІРҪС– СҒРёСҒСӮРөРјРё РҪР°СҒСӮСғРҝРҪРҫРіРҫ РҝРҫРәРҫліРҪРҪСҸ РҝРөСҖРөРҙРұР°СҮР°СӮРёРјСғСӮСҢ РҝРҫСӮСҖРөРұРё РҪР° РҫСҒРҪРҫРІС– РәРҫРҪСӮРөРәСҒСӮСғ, С–СҒСӮРҫСҖС–С— РәРҫСҖРёСҒСӮСғРІР°СҮР° СӮР° СҒРёРіРҪалів РҪавРәРҫлиСҲРҪСҢРҫРіРҫ СҒРөСҖРөРҙРҫРІРёСүР°. РЎРёСҒСӮРөРјР° РјРҫР¶Рө РҝРҫРјС–СӮРёСӮРё, СүРҫ РІРё РҝлаРҪСғС”СӮРө РәС–Р»СҢРәР° Р·СғСҒСӮСҖС–СҮРөР№ Сғ РҪРөР·РҪайРҫРјРҫРјСғ РјС–СҒСӮС–, С– РҝСҖРҫР°РәСӮРёРІРҪРҫ РҝСҖРҫРҝРҫРҪСғРІР°СӮРё РІР°СҖС–Р°РҪСӮРё СӮСҖР°РҪСҒРҝРҫСҖСӮСғ Р°РұРҫ РҝСҖРҫРіРҪРҫР·Рё РҝРҫРіРҫРҙРё. Р‘РөР·СҲРҫРІРҪР° РјСғР»СҢСӮРёРјРҫРҙалСҢРҪР° С–РҪСӮРөРіСҖР°СҶС–СҸ: РңайРұСғСӮРҪС– СҒРёСҒСӮРөРјРё РІРёР№РҙСғСӮСҢ Р·Р° СҖамРәРё РҝСҖРҫСҒСӮРҫС— РҝС–РҙСӮСҖРёРјРәРё СҖС–Р·РҪРёС… РјРҫРҙалСҢРҪРҫСҒСӮРөР№ СӮР° РұРөР·СҲРҫРІРҪРҫ С—С… С–РҪСӮРөРіСҖСғРІР°СӮРёРјСғСӮСҢ. Р РҫР·РјРҫРІР° РјРҫР¶Рө РҝСҖРёСҖРҫРҙРҪРҫ РҝСҖРҫСӮС–РәР°СӮРё РјС–Р¶ СӮРөРәСҒСӮРҫРј, РіРҫР»РҫСҒРҫРј, Р·РҫРұСҖажРөРҪРҪСҸРјРё СӮР° С–РҪСӮРөСҖР°РәСӮРёРІРҪРёРјРё РөР»РөРјРөРҪСӮами, РІРёРұРёСҖР°СҺСҮРё РҝСҖавилСҢРҪРёР№ СҒРҝРҫСҒС–Рұ РҙР»СҸ РәРҫР¶РҪРҫРіРҫ С„СҖагмРөРҪСӮР° С–РҪС„РҫСҖРјР°СҶС–С— РұРөР· РҪРөРҫРұС…С–РҙРҪРҫСҒСӮС– СҸРІРҪРҫРіРҫ РІРёРұРҫСҖСғ РәРҫСҖРёСҒСӮСғРІР°СҮР°. РЎРҝРөСҶіалізРҫРІР°РҪС– РөРәСҒРҝРөСҖСӮРё РІ галСғР·С–: РҘРҫСҮР° СғРҪС–РІРөСҖСҒалСҢРҪС– РҝРҫРјС–СҮРҪРёРәРё РҝСҖРҫРҙРҫРІР¶СғРІР°СӮРёРјСғСӮСҢ СғРҙРҫСҒРәРҫРҪалСҺРІР°СӮРёСҒСҸ, РјРё СӮР°РәРҫР¶ РҝРҫРұР°СҮРёРјРҫ Р·СҖРҫСҒСӮР°РҪРҪСҸ РІРёСҒРҫРәРҫСҒРҝРөСҶіалізРҫРІР°РҪРҫРіРҫ СҖРҫР·РјРҫРІРҪРҫРіРҫ РЁРҶ Р· глиРұРҫРәРёРј РҙРҫСҒРІС–РҙРҫРј Сғ РҝРөРІРҪРёС… галСғР·СҸС… вҖ“ СҺСҖРёСҒСӮРё, СҸРәС– СҖРҫР·СғРјС–СҺСӮСҢ СҒСғРҙРҫРІСғ РҝСҖР°РәСӮРёРәСғ СӮР° РҝСҖРөСҶРөРҙРөРҪСӮРё, РјРөРҙРёСҮРҪС– СҒРёСҒСӮРөРјРё Р· глиРұРҫРәРёРјРё Р·РҪР°РҪРҪСҸРјРё РҝСҖРҫ взаємРҫРҙС–СҺ ліРәС–РІ СӮР° РҝСҖРҫСӮРҫРәРҫли ліРәСғРІР°РҪРҪСҸ, Р°РұРҫ фіРҪР°РҪСҒРҫРІС– РәРҫРҪСҒСғР»СҢСӮР°РҪСӮРё, СҸРәС– РҫРұС–Р·РҪР°РҪС– Р· РҝРҫРҙР°СӮРәРҫРІРёРјРё РәРҫРҙРөРәСҒами СӮР° С–РҪРІРөСҒСӮРёСҶС–Р№РҪРёРјРё СҒСӮСҖР°СӮРөРіС–СҸРјРё. ДійСҒРҪРҫ РұРөР·РҝРөСҖРөСҖРІРҪРө РҪавСҮР°РҪРҪСҸ: РңайРұСғСӮРҪС– СҒРёСҒСӮРөРјРё РІРёР№РҙСғСӮСҢ Р·Р° СҖамРәРё РҝРөСҖС–РҫРҙРёСҮРҪРҫРіРҫ РҝРөСҖРөРҝС–РҙРіРҫСӮРҫРІРәРё СӮР° РҝРөСҖРөР№РҙСғСӮСҢ РҙРҫ РұРөР·РҝРөСҖРөСҖРІРҪРҫРіРҫ РҪавСҮР°РҪРҪСҸ РҪР° РҫСҒРҪРҫРІС– взаємРҫРҙС–Р№, СҒСӮР°СҺСҮРё Р· СҮР°СҒРҫРј РұС–Р»СҢСҲ РәРҫСҖРёСҒРҪРёРјРё СӮР° РҝРөСҖСҒРҫРҪалізРҫРІР°РҪРёРјРё, Р·РұРөСҖС–РіР°СҺСҮРё РҝСҖРё СҶСҢРҫРјСғ РІС–РҙРҝРҫРІС–РҙРҪС– РіР°СҖР°РҪСӮС–С— РәРҫРҪфіРҙРөРҪСҶС–Р№РҪРҫСҒСӮС–. РқРөзважаСҺСҮРё РҪР° СҶС– захРҫРҝливі РјРҫжливРҫСҒСӮС–, РҝСҖРҫРұР»РөРјРё залиСҲР°СҺСӮСҢСҒСҸ. РҹСҖРҫРұР»РөРјРё РәРҫРҪфіРҙРөРҪСҶС–Р№РҪРҫСҒСӮС–, Р·РјРөРҪСҲРөРҪРҪСҸ СғРҝРөСҖРөРҙР¶РөРҪРҫСҒСӮС–, РҪалРөР¶РҪР° РҝСҖРҫР·РҫСҖС–СҒСӮСҢ СӮР° РІСҒСӮР°РҪРҫРІР»РөРҪРҪСҸ РҪалРөР¶РҪРҫРіРҫ СҖС–РІРҪСҸ Р»СҺРҙСҒСҢРәРҫРіРҫ РәРҫРҪСӮСҖРҫР»СҺ вҖ“ СҶРө РҝРҫСҒСӮС–Р№РҪС– РҝРёСӮР°РҪРҪСҸ, СҸРәС– С„РҫСҖРјСғРІР°СӮРёРјСғСӮСҢ СҸРә СӮРөС…РҪРҫР»РҫРіС–СҺ, СӮР°Рә С– С—С— СҖРөРіСғР»СҺРІР°РҪРҪСҸ. РқайСғСҒРҝС–СҲРҪС–СҲРёРјРё РІРҝСҖРҫРІР°РҙР¶РөРҪРҪСҸРјРё РұСғРҙСғСӮСҢ СӮС–, СүРҫ РҝСҖРҫРҙСғРјР°РҪРҫ РІРёСҖС–СҲР°СӮСҢ СҶС– РҝСҖРҫРұР»РөРјРё, РІРҫРҙРҪРҫСҮР°СҒ РҪР°РҙР°СҺСҮРё СҒРҝСҖавжРҪСҺ СҶС–РҪРҪС–СҒСӮСҢ РәРҫСҖРёСҒСӮСғРІР°СҮам. РһСҮРөРІРёРҙРҪРҫ, СүРҫ СҖРҫР·РјРҫРІРҪРёР№ РЁРҶ РҝРөСҖРөР№СҲРҫРІ РІС–Рҙ РҪС–СҲРөРІРҫС— СӮРөС…РҪРҫР»РҫРіС–С— РҙРҫ РҝР°СҖР°РҙРёРіРјРё РјРөР№РҪСҒСӮСҖС–РјРҪРҫРіРҫ С–РҪСӮРөСҖС„РөР№СҒСғ, СҸРәР° РІСҒРө РұС–Р»СҢСҲРө РҫРҝРҫСҒРөСҖРөРҙРәРҫРІСғРІР°СӮРёРјРө РҪР°СҲСғ взаємРҫРҙС–СҺ Р· СҶРёС„СҖРҫРІРёРјРё СҒРёСҒСӮРөмами. ЕвРҫР»СҺСҶС–Р№РҪРёР№ СҲР»СҸС… РІС–Рҙ РҝСҖРҫСҒСӮРҫРіРҫ Р·С–СҒСӮавлРөРҪРҪСҸ Р·С– Р·СҖазРәами ELIZA РҙРҫ СҒСғСҮР°СҒРҪРёС… СҒРәлаРҙРҪРёС… РјРҫРІРҪРёС… РјРҫРҙРөР»РөР№ С” РҫРҙРҪРёРј С–Р· РҪайважливіСҲРёС… РҙРҫСҒСҸРіРҪРөРҪСҢ Сғ взаємРҫРҙС–С— Р»СҺРҙРёРҪРё Р· РәРҫРјРҝ'СҺСӮРөСҖРҫРј вҖ“ С– СҶРөР№ СҲР»СҸС… СүРө РҙалРөРәРҫ РҪРө завРөСҖСҲРөРҪРёР№.





